

出处:CVPR2021 (oral)
任务是: 大尺度超分辨率(8$\times$ 到 64$\times$),most details and textures are lost during downsampling.
motivation
- 已有的SR方法:
- solely rely on $L_2$ loss: 视觉质量不好 (over-smoothing artifacts)。
- adverssrial loss [ESRGAN]: Generator既要捕获图像characteristics又要保真(maintaining the fidelity to the GT), 限制了其近似自然图像的能力,产生artifacts
- GAN inversion methods [PULSE]:反转pre-trained GAN的生成过程:把image mapping回latent space;再由latent space中optimal vector重建图像。只靠低维隐向量不足以指导重建的过程,使得产生的结果low fidelity. 需要image-specific, iterative的优化.
- 利用pre-trained GAN作为latent bank, 充分利用pre-trained GAN中封装的丰富且多样的先验。换用不同的bank可以不同类的图像:cat,building,human face,car. 利用字典学习的方式,测试阶段,只需要一次前传即可得到恢复后的图像。
- GLEAN 的整体结构:encoder-bank-decoder
related work
large-factor SR
- fully probabilistic pixel recursive network for upsampling extremely coarse images with resolution 8×8. (Ryan Dahl, Mohammad Norouzi, and Jonathon Shlens. Pixel recursive super resolution. In ICCV, 2017.)
- RFB-ESRGAN:adopts multi-scale receptive fields blocks for 16× SR. (Taizhang Shang, Qiuju Dai, Shengchen Zhu, Tong Yang, and Yandong Guo. Perceptual extreme super resolution network with receptive field block. In CVPRW, 2020.)
- VarSR: 8× SR by matching the latent distributions of LR and HR images to recover the missing details. (Sangeek Hyun and Jae-Pil Heo. VarSR: Variational super-resolution network for very low resolution images. In ECCV, 2020.)
- perform 16× reference-based SR on paintings with a non-local matching module and a wavelet texture loss. (Yulun Zhang, Zhifei Zhang, Stephen DiVerdi, Zhaowen Wang, Jose Echevarria, and Yun Fu. Texture hallucination for large-scale painting super-resolution. In ECCV, 2020.)
GAN inversion
David Bau, Hendrik Strobelt, William Peebles, Bolei Zhou, Jun-Yan Zhu, Antonio Torralba, et al. Semantic photo manipulation with a generative image prior. TOG, 2020.
Jinjin Gu, Yujun Shen, and Bolei Zhou. Image processing using multi-code GAN prior. In CVPR, 2020.
Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, and Cynthia Rudin. PULSE: Self-supervised photo upsampling via latent space exploration of generative models. In CVPR, 2020.
通过pixel-wise约束,迭代优化styleGAN的隐变量。
Xingang Pan, Xiaohang Zhan, Bo Dai, Dahua Lin, Chen Change Loy, and Ping Luo. Exploiting deep generative prior for versatile image restoration and manipulation. In ECCV, 2020.
finetune generator和latent code来缩小训练集和测试集分布的gap.
降质图像$x$,latent space:$\mathcal{Z}$:
缺点:
低维的隐向量不能保持图像的spatial information.
方法
passing both the latent vectors and multi-resolution convolutional features from the encoder.
multi-resolution cues need to be passed from the bank to the decoder.
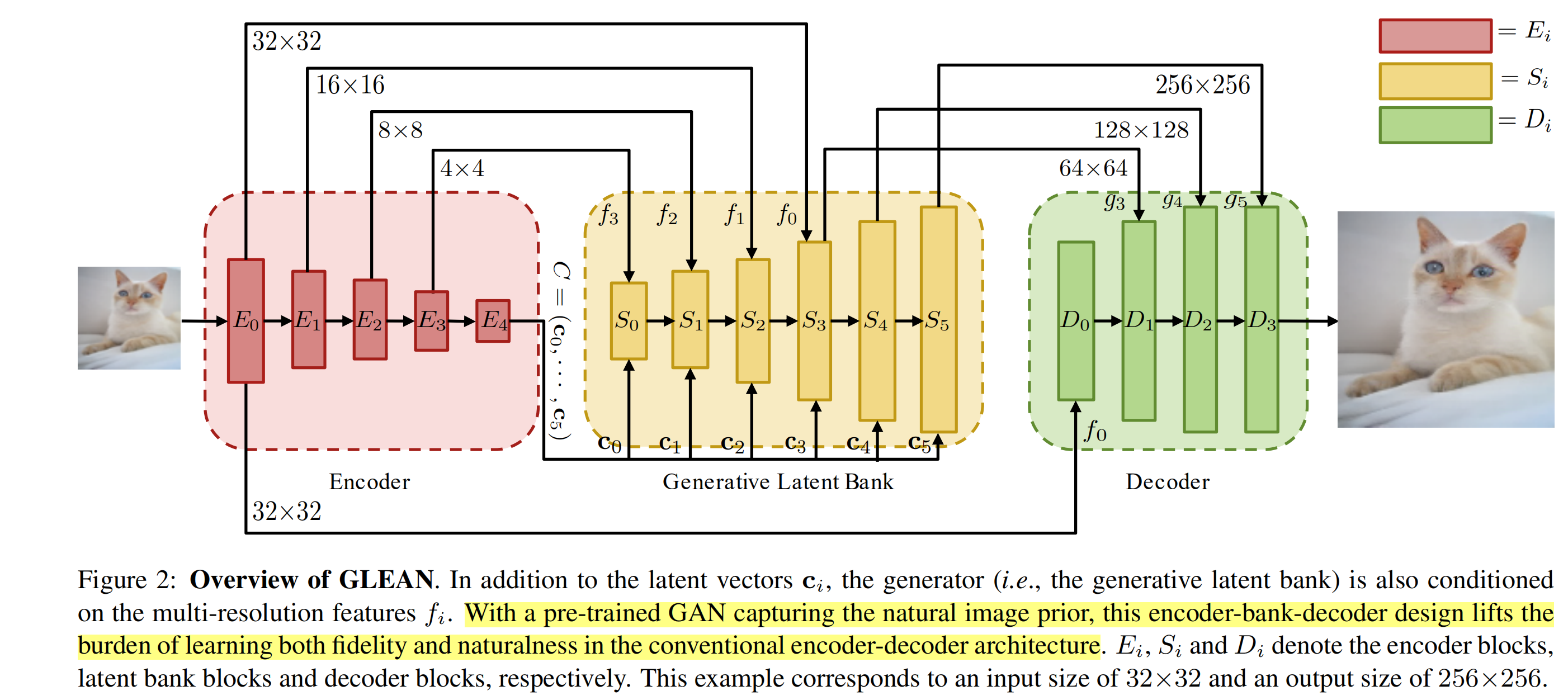
- 整个结构为encoder-bank-decoder
- encoder:$E_0$为RRDB-Net,$E_i, i \in\{1,…,N\}$代表堆叠一个stride=2的conv和一个stride=1的conv. 最后由FC层得到$C$, $C$表示隐向量,提供high-level信息。为了更好的指导结构重建,将多分辨率的特征和隐向量都送入bank.
- Generative latent bank: 用pre-trained的Generator, styleGAN,提供纹理和细节生成的先验。
- 对generator的每个block输入不同的隐向量$C_i$, $i \in \{0,…,k-1\}$
- $\{g_i\}$代表每个block输出的feature, 它是由$C_i, g_{i-1}, f_{N-i}$由augmented style block得到。
- 不直接输出结果,而是将特征$\{g_i\}$输入到decoder
- 优势:像reference-based SR,HR reference image作为显式图像字典。性能很受 输入和reference相似度的影响。GLEAN用GAN-based的字典,不依赖于任何具体的图像,它获取的是图像的分布。而且没有global matching和reference images selection, 计算简便。
- decoder:progressive地聚合来自encoder和latent bank的特征。每个conv后跟着pixel-shuffle层。由于有encoder和decoder之间的skip-connection,encoder捕获的信息可以被强化,bank专注于纹理和细节的生成。
- 训练:$\mathcal{l_2}$ loss, perceptual loss, adversarial loss. 训练时fix住latent bank,实验发现,finetune latent bank没有性能提升,而且可能使latent bank偏向训练集的分布。
主要结果


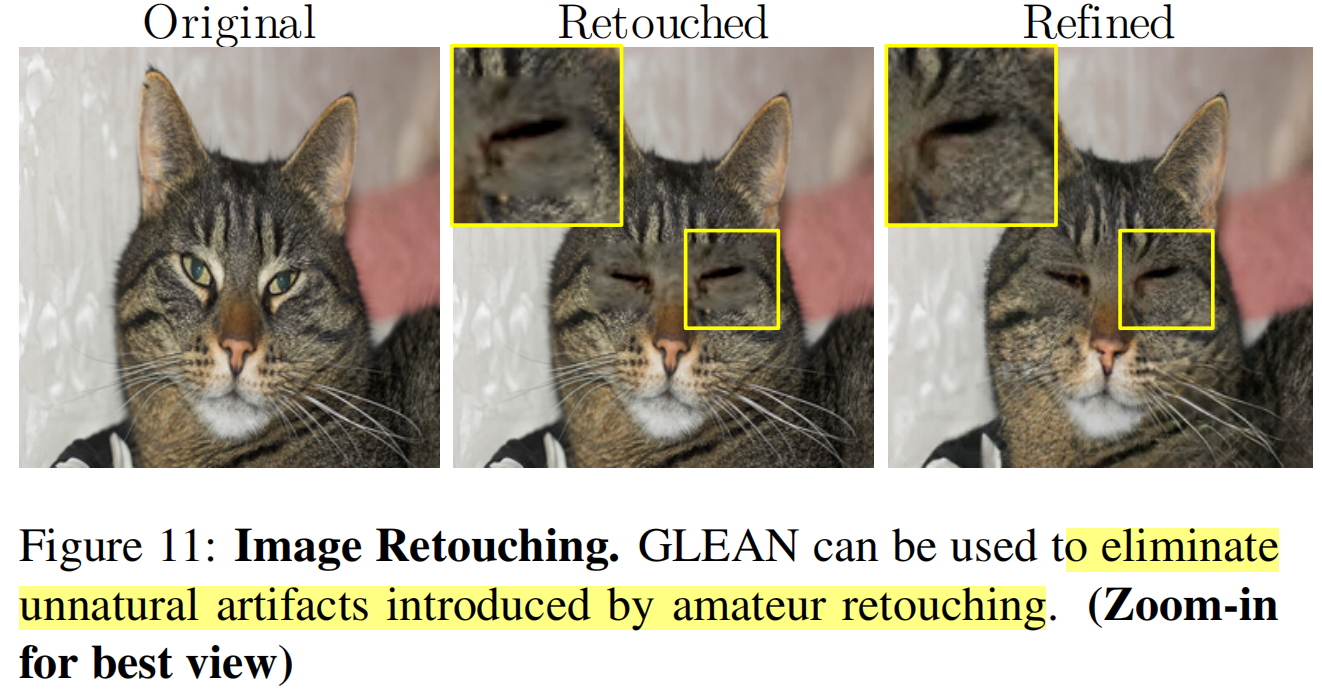
image retouching
参考文献:
[ESRGAN]: Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Chen Change Loy, Yu Qiao, and Xiaoou Tang. ESRGAN: Enhanced super-resolution generative adversarial networks. In ECCVW, 2018.
[PULSE]: Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi, and Cynthia Rudin. PULSE: Self-supervised photo upsampling via latent space exploration of generative models. In CVPR, 2020.
reference-based SR
- Xiaoming Li, Chaofeng Chen, Shangchen Zhou, Xianhui Lin, Wangmeng Zuo, and Lei Zhang. Blind face restoration via deep multi-scale component dictionaries. In ECCV, 2020.
- Xiaoming Li, Wenyu Li, Dongwei Ren, Hongzhi Zhang, Meng Wang, and Wangmeng Zuo. Enhanced blind face restoration with multi-exemplar images and adaptive spatial feature fusion. In CVPR, 2020.
- Xu Yan, Weibing Zhao, Kun Yuan, Ruimao Zhang, Zhen Li, and Shuguang Cui. Towards content-independent multi-reference super-resolution: Adaptive pattern matching and feature aggregation. In ECCV, 2020.
- Yang Zhang, Ivor W Tsang, Yawei Luo, Changhui Hu, Xiaobo Lu, and Xin Yu. Copy and Paste GAN: Face hallucination from shaded thumbnails. In CVPR, 2020.
- Zhifei Zhang, Zhaowen Wang, Zhe Lin, and Hairong Qi. Image super-resolution by neural texture transfer. In CVPR, 2019.