

出处:CVPR2020 (oral)
motivation
在不增加计算开销的前提下提高语义分割的性能,而语义分割依赖于HR feature representations,如果直接输入HR images会产生很大的计算开销,所以做SSSR。而只依赖于SSSR的decoder难以恢复original details,所以他们用了SISR来guide SSSR,如何guide呢?用feature affinity module,核心是feature相似矩阵的距离。
related works
现有的语义分割方法能取得好的性能依赖于HR的深度特征表示:large computation budgets
现有的语义分割方法保持HR representations:
- 用空洞卷积代替 strided 卷积,比如DeepLabs
- 结合HR的pathway,比如Unet
这些方法的输入通常是original HR image,当限制输入图像的大小的时候,他们的性能有明显的下降。(现有语义分割方法:FCN, DeepLabs, PSPNet, 空洞卷积,pyramid pooling module, attention, context encoding)
现有的轻量级的语音分割:通过factorization加速卷积,ESPNets(split-merge,reduce-expand加速卷积计算),采用一些有效的分类网络(mobileNet、shuffleNet),知识蒸馏帮助训练对抗网络。但他们的性能比SOTA差很多。
本文提出一种two-stream的framework (dual super-resolution learning, DSRL) 在不产生额外计算开销的情况下提高semantic 分割的准确率: 对于LR的输入保持HR representations。具体的,SISR得到的HR features用来guide spatial维度的相关性学习。DSRL可以在相同的resolution下,显著提高准确率。
现有的SISR方法:
- pre-upsampling SR:先通过bicubic上采样得到HR图像,再用网络refine HR图像(计算开销大:网络在HR上做的)
- post-upsampling SR:在网络的最后面用可学习的上采样层
- progressive SR:逐渐提高分辨率,可以handle multi-scale的SR(deep laplacian pyramid networks)
- iterative up-and-down SR:通过iterative上\下采样的层得到中间图像,结合中间图像重建最终图像(deep back-projection networks)
multi tasks:
mask R-cnn(检测+实例分割)
RCNN(姿态估计+动作识别)
cross tasks:
(希望把语义分割作为主要任务,SISR作为附加任务)
proposed method
Review of encoder-decoder framework
用来提取特征的encoder的scaling step是2,OS通常是8或者16(the ratio of input image spatial resolution to the Encoder output resolution),把最后两层strided conv换成空洞卷积。在decoder端,用一个bilinear 上采样层恢复分辨率。
现有的方法只能将feature上采样至与input image同样的大小,可能比original image小。(分割网络的输入往往是对原图做了下采样)。这样可能损失了一部分有用的label信息,另一方面,也难以只依赖decoder恢复original details。
DSRL
contribution:
- 在不额外增加计算开销的前提下,通过保持HR representations,提高性能
- 泛化性:可以扩展到需要HR representation的任务中,比如人体姿态估计
- 实验:在语音分割和人体姿态估计任务上都获得了良好的性能,相同计算开销,提高2%
包含三个部分:
- semantic segmentation super-resolution (SSSR)
- single image super-resolution (SISR)
- feature affinity (FA)
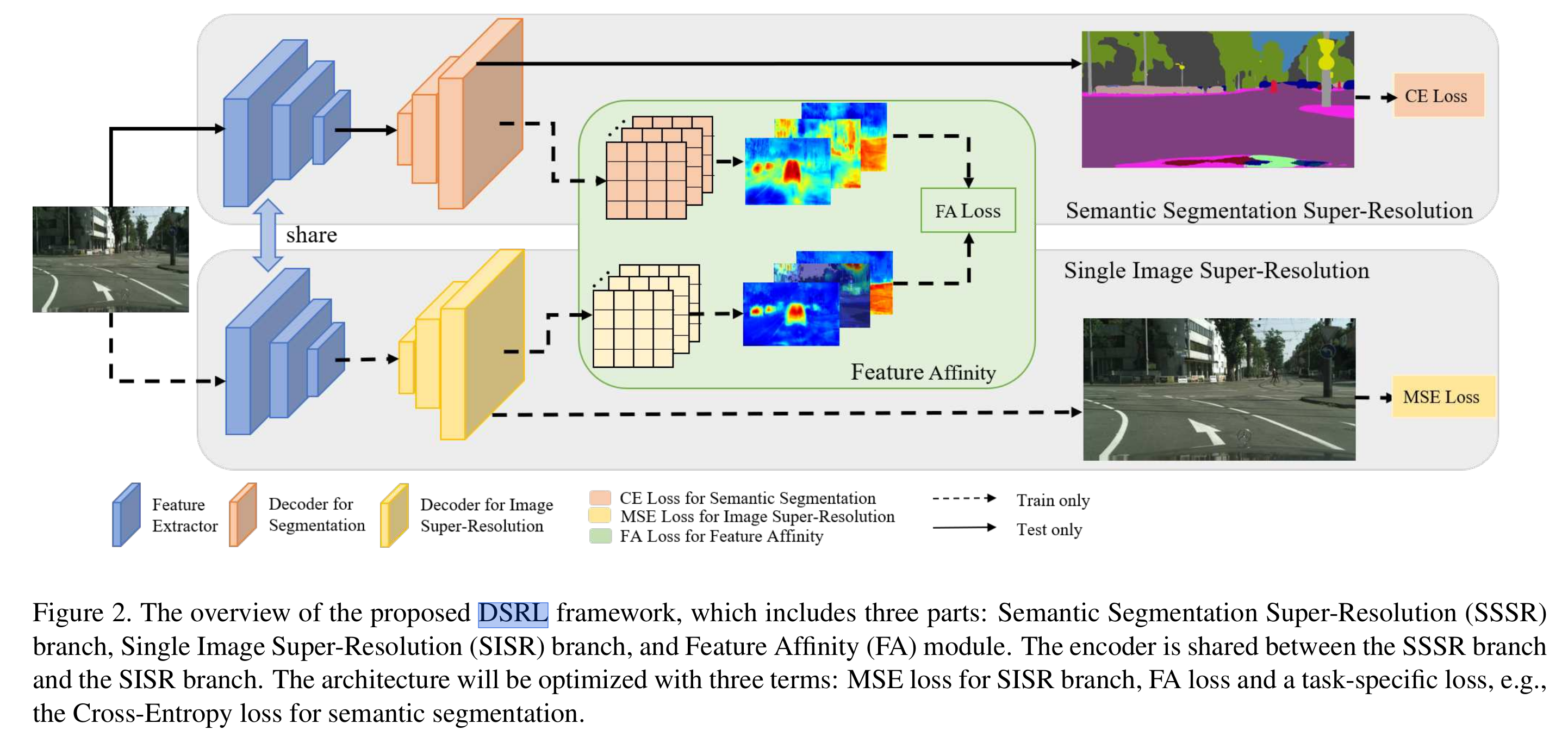
其中SISR与SSSR共享特征提取器,
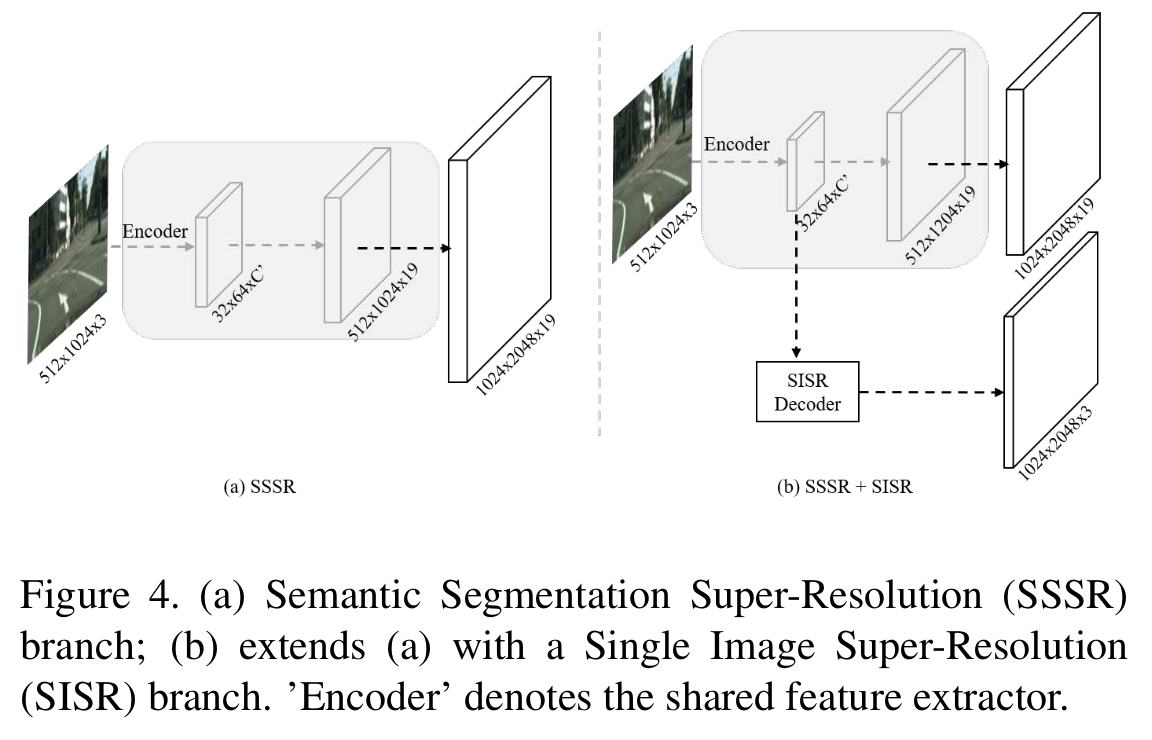
SSSR:加额外的上采样层(一些deconv)来得到最终的prediction mask,比如输入的是5121024,输出1024\2048. 他们的方法可以利用全部的label
SISR:只依赖decoder不足够恢复HR semantic特征表示,因为decoder的上采样结构不是简单的bilinear上采样,就是简单的sub-net,这并不会引入额外的信息,因为输入是LR的。 而SISR可以有效恢复图像细节,SSSR和SISR的feature如下图所示,SISR的feature包含更多的物体更多的复杂结构,尽管这些结构不能直接揭示物体属于哪一类,但他们可以根据像素与像素、区域与区域直接的相关性group起来,而这些像素区域的关联揭示了语义信息。
所以,SISR得到的HR feature用来guide SSSR的HR feature的学习。SISR根据original image的GT来优化。
FA: feature affinity SISR得到的structure information如何guide SSSR?用 feature affinity learning,FA来学习SSSR和SISR feature上相似矩阵的距离,相似矩阵刻画的是像素直接pairwise的关系。理论上,应该计算所有像素对的affinity,为了节省计算开销,他们subsamples得到1/8的像素对。为了减少由SISR和SSSR不一致引起的训练的不稳定性,他们还附加了一个feature transform模块。
最后的FA loss为:
$p=2, q=1$,总的loss:
其中,
$L_{ce}$ 为cross entropy loss, $w_1=0.1, w_2=1.0$
experiments
semantic segmentation:CitySpace数据集,将一张图分为19类。10242048;CamVid数据集,11类,960\720。
metric:mIoU(mean Intersection over Union)
segmentation architecture: ESPNetv2, DeepLabv3+(ablation study), PSPNet, BiseNet, DABNet (lightweight)
effect of components
输入:256512(resize, 1024\2048=>256*512)
输出:+SR的输出是5121024(2倍),不加SR的输出:256\512
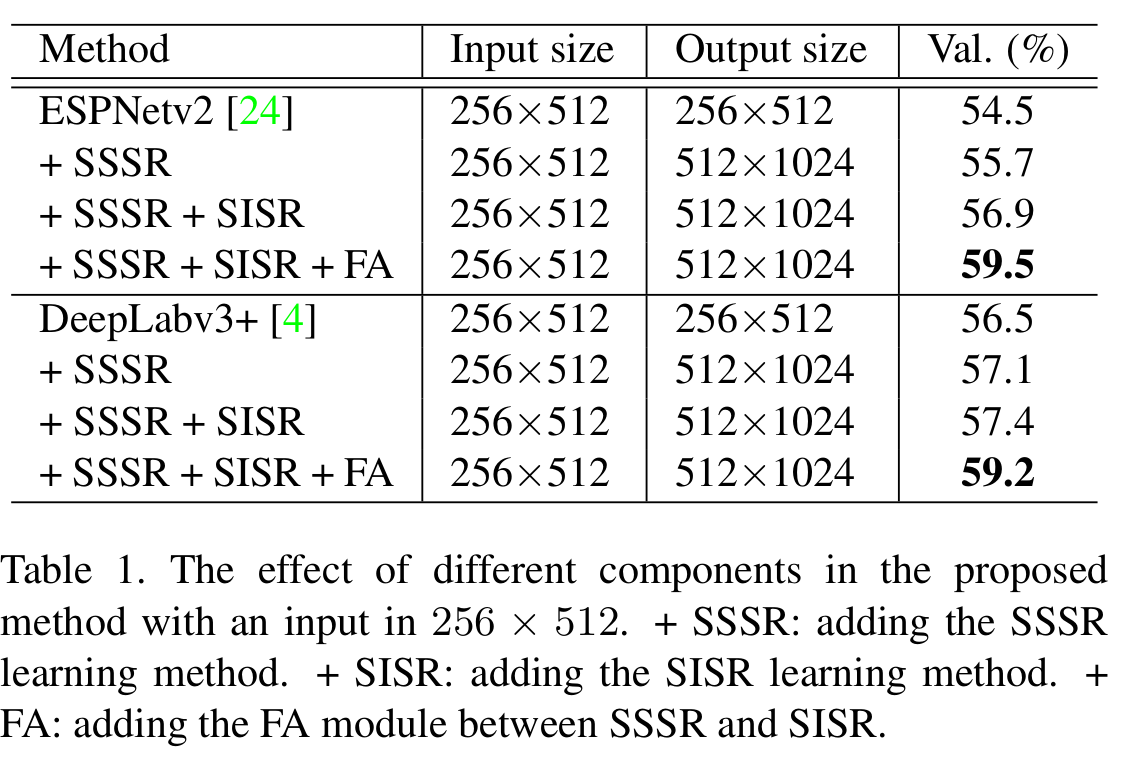
+SSSR+SISR+FA > +SSSR+SISR > SSSR > 不加
原图下采样作为baseline和自己方法的输入,输出分辨率不同
【输出分辨率不同怎么比的?】
把原图的label分别下采样到256*512和512*1024比
output统统上采样到原图的分辨率(1024*2048)和label比。(保持同分辨率下比较,并且不对原始的label降质)
第2 种比较相当于比的是bicubic+seg和SR+seg
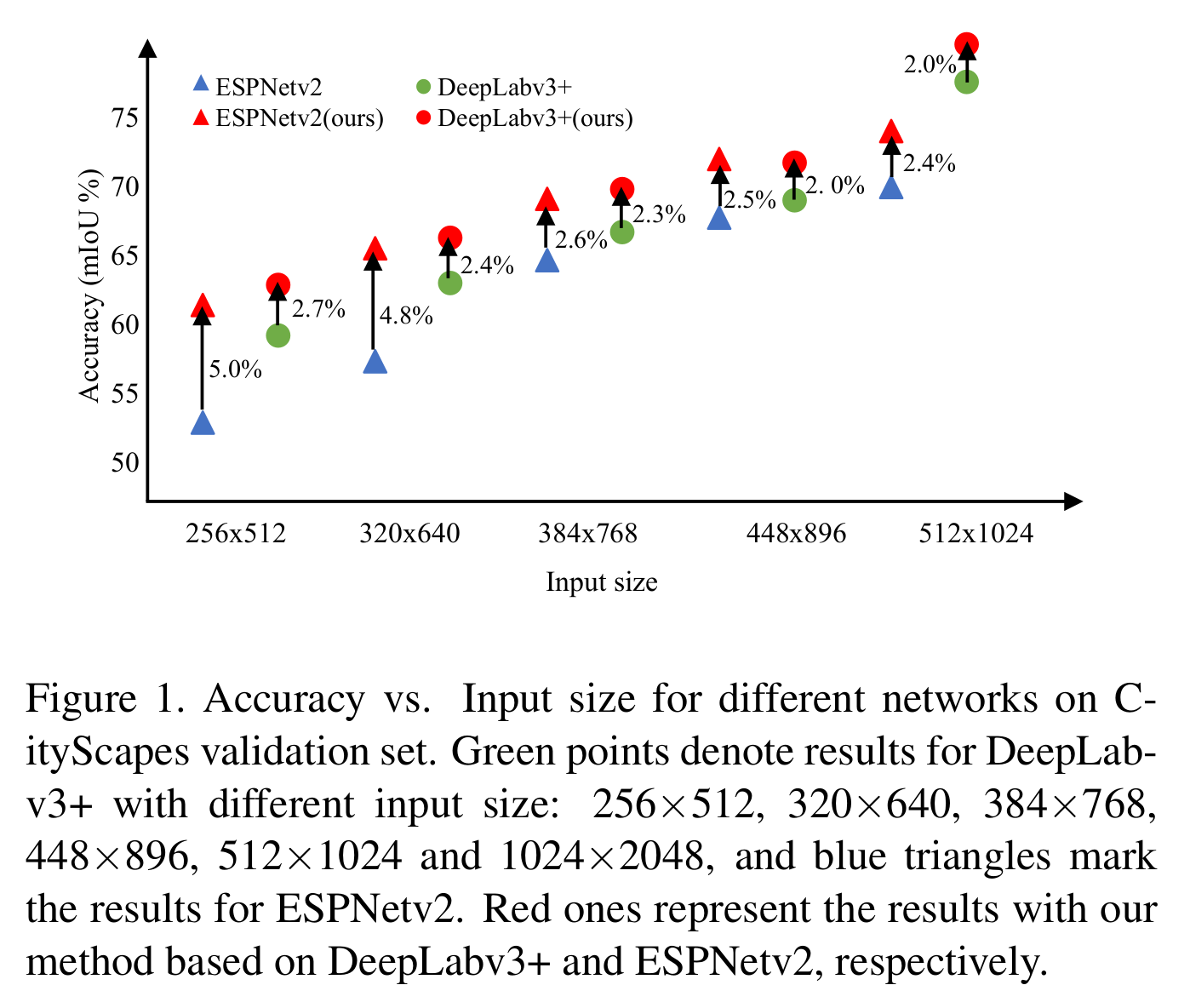
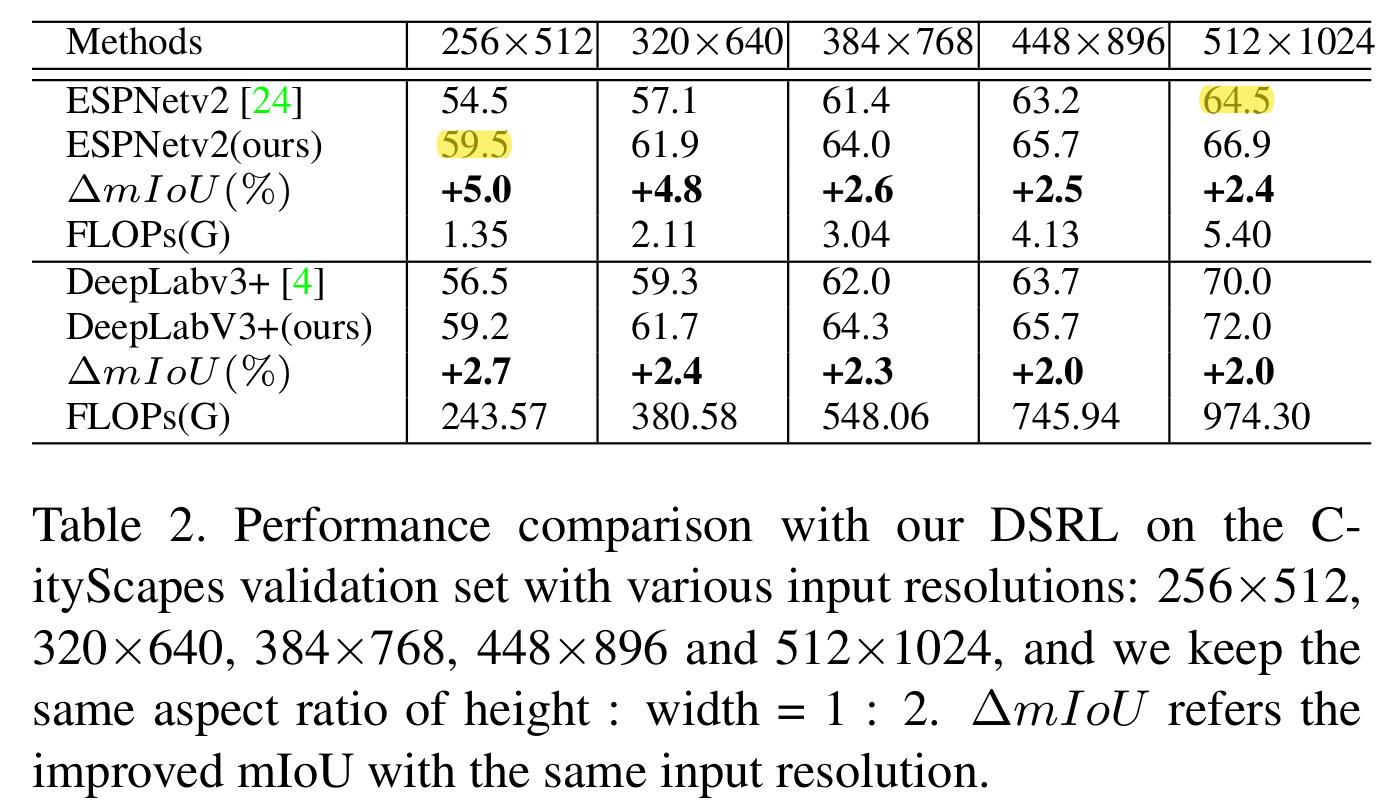
effect of various input resolutions
input resolution:256*512, 320*640, 384*768, 448*896, 512*1024 (CitySpace)
对于每一种input resolution,用他们的framework都比不用性能好,且随着input resolution逐渐增大,性能增值越来越小。
human pose estimation
metric:object keypoint similarity (OKS)
architecture: HRNet-w32, 用offline person detection的结果预测关键点
输入human detection box (缩放到固定大小:256192, 162\128, 128*96)
输出heatmap(64*48)
results
visualization of segmentation features
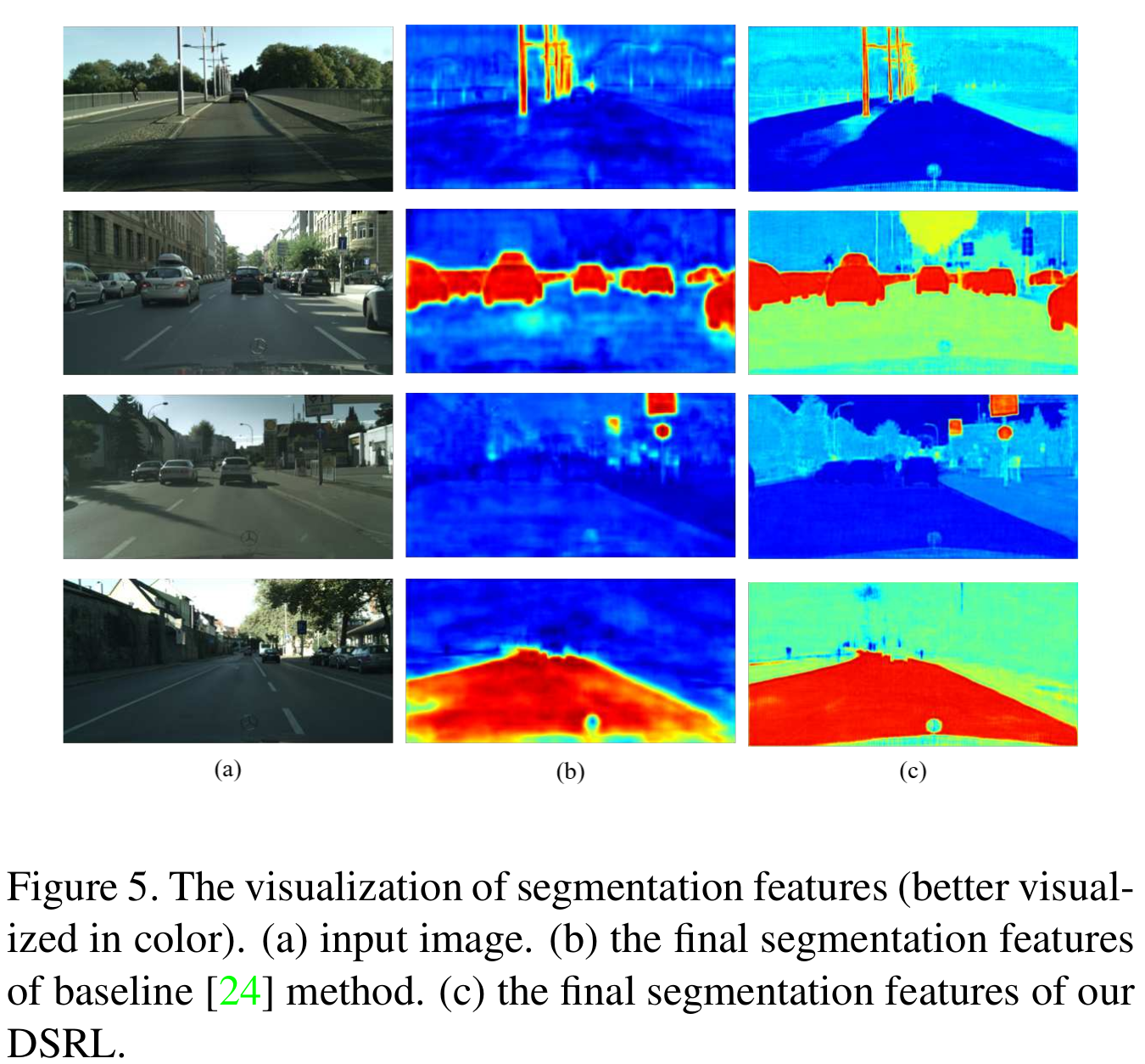
对于structured objection提升尤其明显,比如人,车