

出处:CVPR2020 (oral)
task: 用audio和LR图像做16倍的人脸超分辨率,输入的LR图像非常小:8*8 pixels, 这些图像的很多重要细节都被丢失了。如果LR的人脸图像是从视频中提取的,那么我们也可以得到这个人的音频信息,而audio中带有一些脸部的特征:性别和年龄。结合听觉和视觉,他们提出了一个:先从单独的音轨构建脸部特征的latent 表示,再从LR图像简历脸部特征潜在的表示。然后再fusion这两个表示。
motivation
limited information

ambiguous mapping
=> incorporate alternative source of information: audio

- audio carries information about age and gender, audio tracks are available in videos, audio and visual signals both capture some shared attributes of a person.
contribution
- the first attempt to use audio for image restoration
- use both audio and a LR image to perform extreme face super-resolution ($16\times$)
- do not use human annotation and thus can be easily trained with video datasets
- 建立了图像和音频的分解表示,因此它可以混合来自不同视频的LR图像和音频,并生成语义上有意义的真实面孔。(our model builds a factorized representation of images and audio as it allows one to mix low-resolution images and audio from different videos and to generate realistic faces with semantically meaningful combinations. )
related works
speech2Face
audio to image: speech2Face [CVPR 2019: Speech2face: Learning the face behind a voice]
styleGAN
给定512维随机向量, styleGAN可以从这个向量重构维一张从未见过的人脸照片。
如果训练一个model,是从图片到512维latent encoding, 这个latent encoding可以通过styleGAN还原为原图。(图=>512维latent code=>原图 )
也就是说,可以用这512维向量生成原图。
如果对这512维的空间稍微做点改变?这个超高维的空间对应人脸的不同属性(肤色、年龄、性别)
如何知道年龄对应的维度是哪些?
1、作者一开始会训练一个分类器,分类器的训练样本、label来自于CelebA,40维label中就有一个维度是年龄(作者贴出来的代码里的wp.npy文件我猜就是CELEBA的label文件)
2、分类器收敛后,用个随机噪声z作为stylegan输入,生成图片x,再把这个x送入分类器,得到分类结果y,用个线性变换(或非线性也行)建立起z与y的关系。。。。然后你就可以通过控制y的变换方向来得到z,再生成想要的x了
总之,styleGAN可以从latent code生成逼真的人脸,更重要的是latent code对应人脸不同属性,可以通过改变latent code得到不同的人脸。(比如得到XX小时候的照片)。
Naive end-to-end training
带有两个编码网络的多模态网络,再把encoder的输出concate再一起送入decoding网络得到HR图像。但这种多模态网络以传统的训练方法很难训练好,因为:不同模态的收敛速度不同。
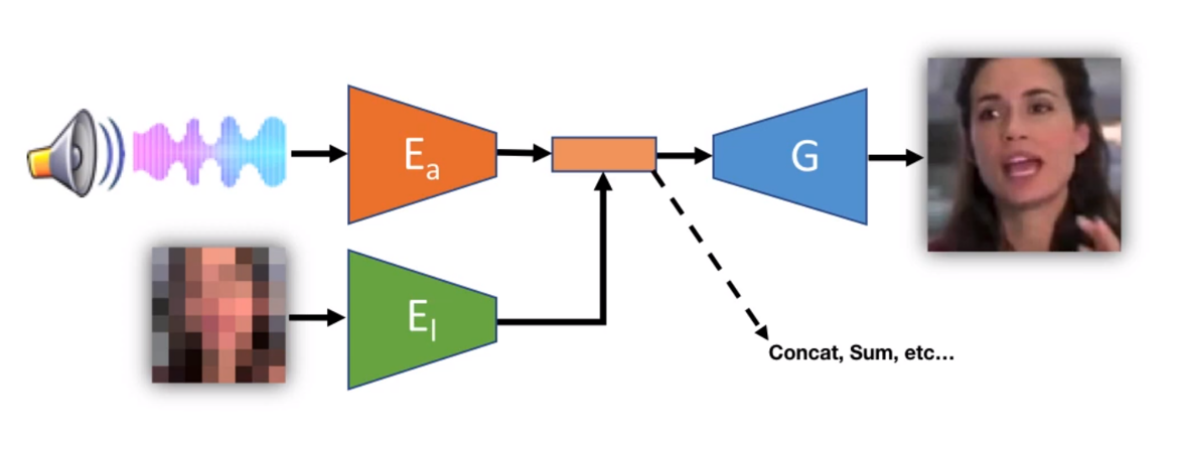

实验发现,这样直接一起训练会忽略audio信号。audio信号需要更长的处理更强的网络来拟合其latent space。
method
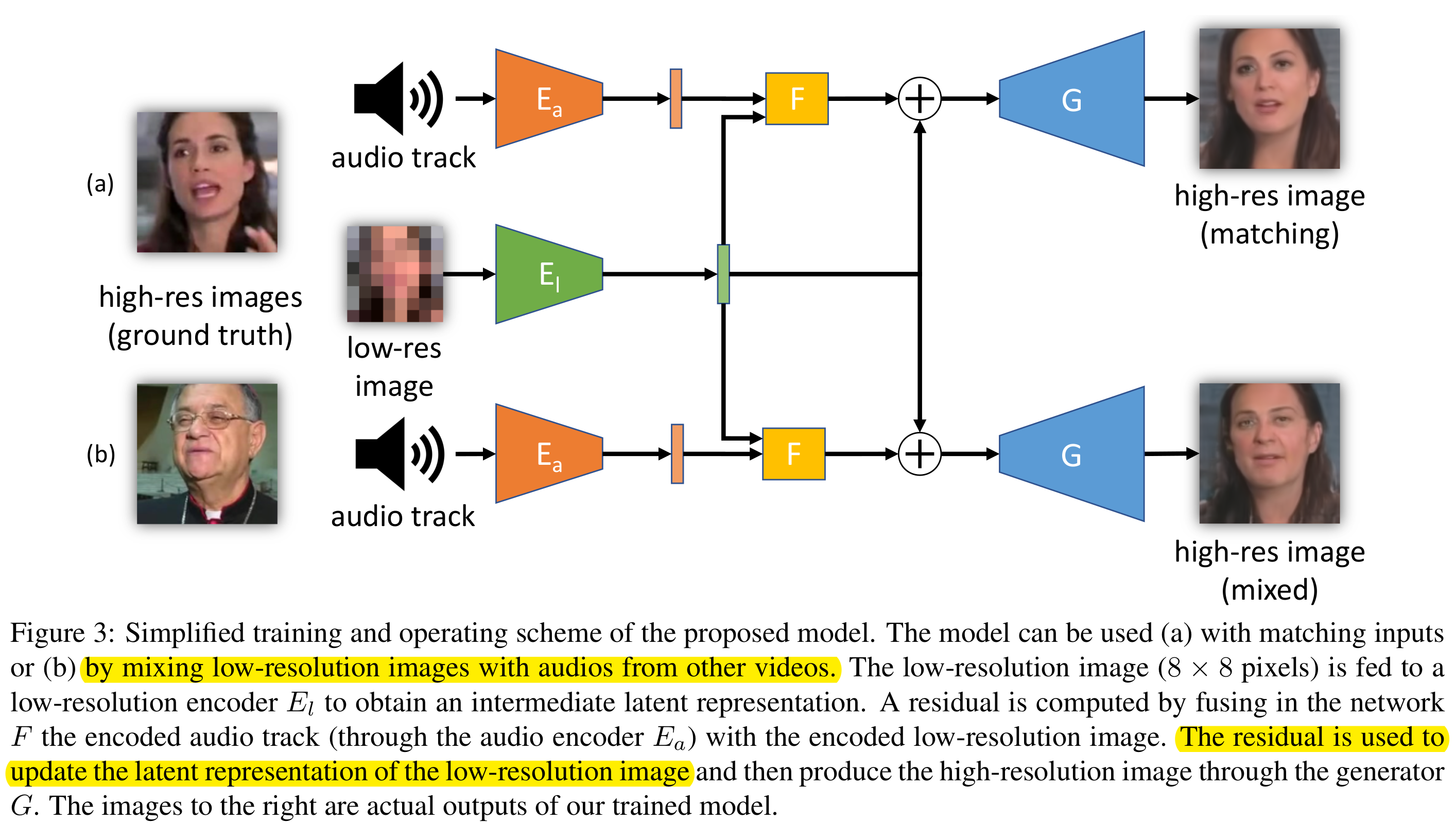
包含这样几个部分:LR encoder $E_l$, audio encoder $E_a$,fusion network $F$, face generator$G$
分开训练LR image encoder和audio encoder,这样他们的解耦精度就相等。fusion: audio作用在LR image固定的中间representation中,这样audio中的人脸属性可以解耦出来。
为什么styleGAN?styleGAN可以通过操控latent code的某些维度,改变生成人脸的某些属性。
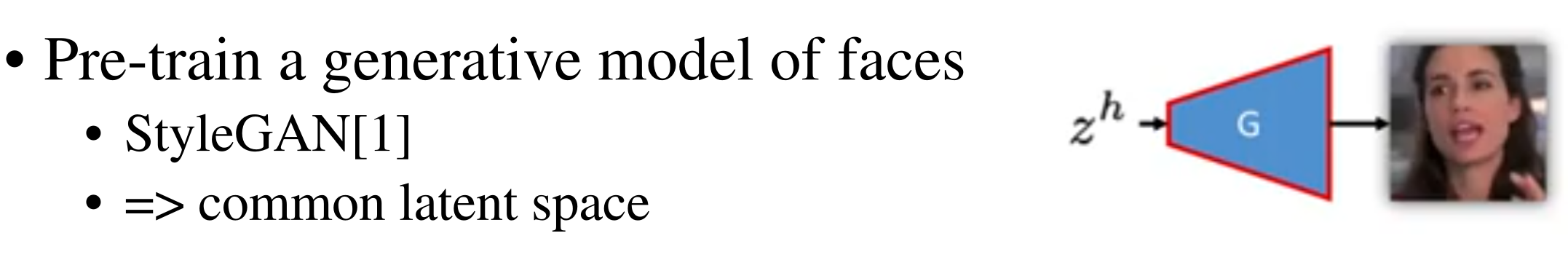
Inverting the Generator
首先训练一个从高斯隐空间$z \sim \mathcal{N}(0,I_d)$(d维)开始的输出高分辨率图像的generator $G(z)$ 【styleGAN: 人脸生成,可以控制所生成图像的高层级属性:头发等,以高斯分布作为输入,输出高质量的samples和隐空间】,再,用自编码器的限制,通过固定$G(z)$得到generator(fixed) 反转后的encoder ($E_h$). 再将这两部分$G(z)$和$E_h$fine-tuning。这个encoder的映射是HR image到generator输入的隐空间,这个$E_h$可以得到图像$x_i$对应的representations ($z_i$)可以当做LR,audio,fusion network的encoder的目标,generator的输出是input HR的近似。【这个模型可以作为生成HR人脸图像的先验,并且中间的representations应该可以由audio编辑】
给定数据集$\mathcal{D}=\{(x_i^h,x_i^l,a_i)|i=1,…,n \}$,
其中$z_i=E_h(x_i^h)$ ,$l_{feat}$ 是perceptual loss (VGG feature)
他们实验发现只回归一个$z_i$不足以很好的恢复$x_i^h$,所以像styleGAN一样,把$z_i$非线性变换得到$w_i$,所以他们生成$k$个不同的$z_{ij},j=1,…,k$. 将非线性变换得到的$w_{ij}$分别插入到generator的不同层。

再fine-tuning:
其中$G_{init}$是styleGAN训练后$G$的权重。训练过程中,总的loss最小后,将$\lambda_t$减小为原来1/2,pre-training和减小正则化:让encoder和decoder逐渐收敛,不至于过早失去G的latent representation的结构
总结,(1). 从标准高斯分布学习G(z)(styleGAN),获得HR 图像的分布
(2). 固定$G(z)$, 用公式1用autoencoder的方式训练reference encoder$E_h$,
(3). fine-tuning $G(z)$和$E_h$,$E_h$可以得到HR图像的latent representations.
Pre-training Low-Res and Audio encoders
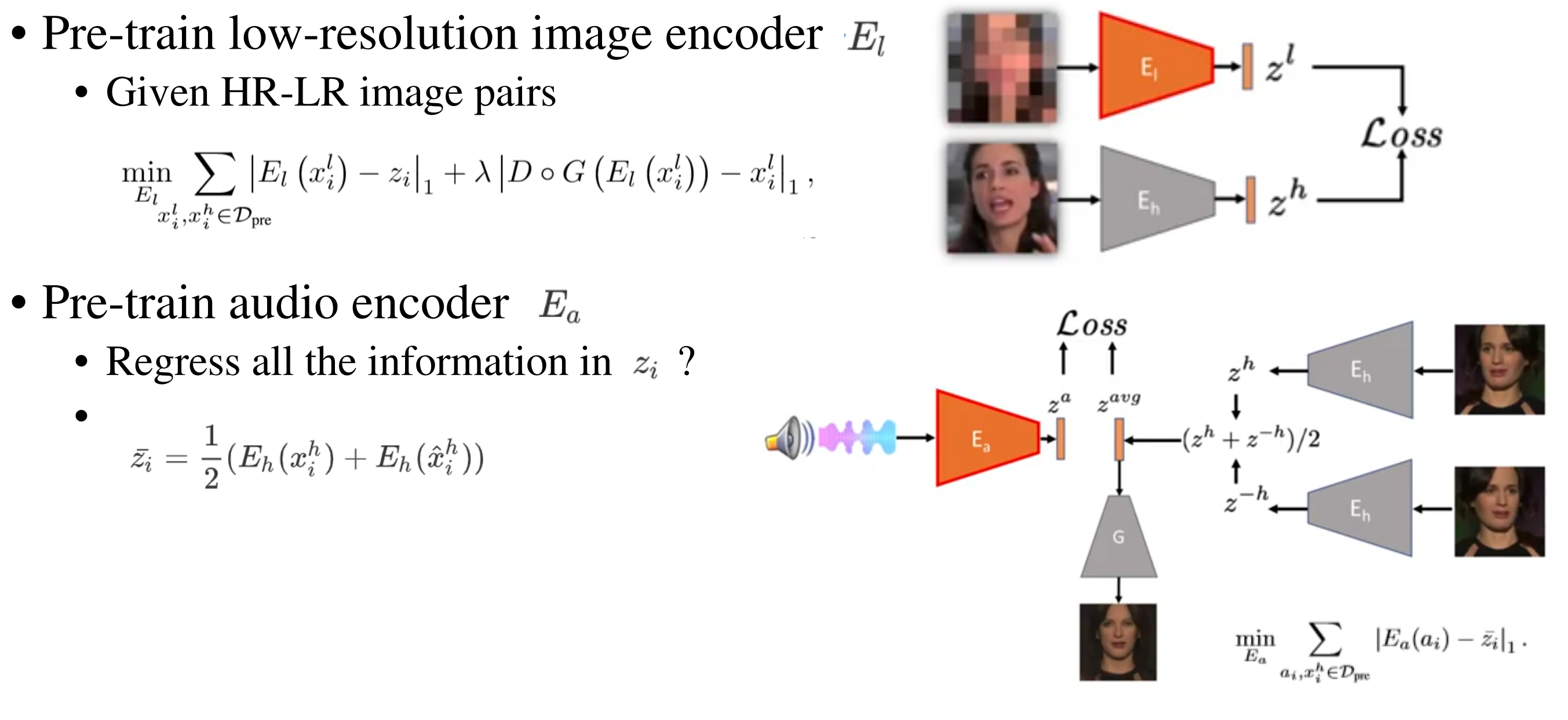
给定HR-LR pair,pre-train一个LR encoder,将输入的LR映射到与HR相同的的reference encoder(前面训练的)输出的latent representations
如果直接训练fusion network,使fusion model$F(x_i^l,a_i)$映射到$z_i=E_h(x_i^h)$,会使网络完全忽略音频信号$a_i$。所以他们先分开训练encoder$E_l$和$E_a$, 让他们尽可能从这两种模态多提取信息,再fusion他们。
为了防止过拟合,pre-train $E_l$和$E_a$时,只用一半数量的训练数据(记为$\mathcal{D}_{pre}$),在fusion的训练阶段用整个训练数据。
训练$E_l$的目标函数:
其中$D \circ x$是$x$的16倍下采样。$\lambda=40$.
前面一项很好理解:希望$E_l$在LR图像$x_i^l$上得到的latent representation与HR图像上的latent representation($z_i=E_h(x_i^h)$)相似。第二项:LR图像$x_i^l$经过encoder(得到HR图像的latent representation)再经过decoder$G$(得到HR图像$x_i^h$)再16倍下采样得到LR 图像$x_i^l$ (因为$x_i^l$与$x_i^h$成pair)
而对于音频encoder:如果将$E_a(a_i)$回归到$z_i$必然有overfitting,因为一些$z_i$中有的属性,$a_i$中没有,比如脸部的姿态(朝左朝右?)。为了消除$z_i$中与$a_i$无关的属性,将$E_a(a_i)$的目标定义为:
这里的 $\hat{x}_i^h$是$x_i^h$的水平翻转版本(将原HR图像水平翻转)。
训练$E_a$的目标函数:
【这里没懂】由于styleGAN的分层的结构,水平翻转的图片的latent code求平均,就消除了音频无法传递的信息。比如图里,输入朝左的面部图像和它水平翻转后的图像(这个水平翻转图像的面部朝向是朝右的),把encoder提取到的latent code求平均,再经过decoder,就得到了朝向正面的图像(消除了音频无法传递的面部朝向信息)。
小结:
audio encoder, fusion network: 固定LR image encoder, 提升他的latent representation 。为了加快audio encoder的训练速度,将HR reference encoder的输出和其水平镜像的平均值作为latent representation 对audio encoder预训练。而这个平均消除了音频无法传递的信息,比如视点。
fusing audio and low-resolution encodings
现在希望聚合pre-train得到的encoder$E_l$和$E_a$提取的信息。由于$E_l$已经是$E_h$的近似,那么希望引入的音频能补出residual:$\Delta z_i=z_i-z_i^l$, 所以fusion network $F$应满足:
因为$E_a$更难训练,所以继续把$E_a$和$F$一起优化。所以,fusion network的优化目标是:
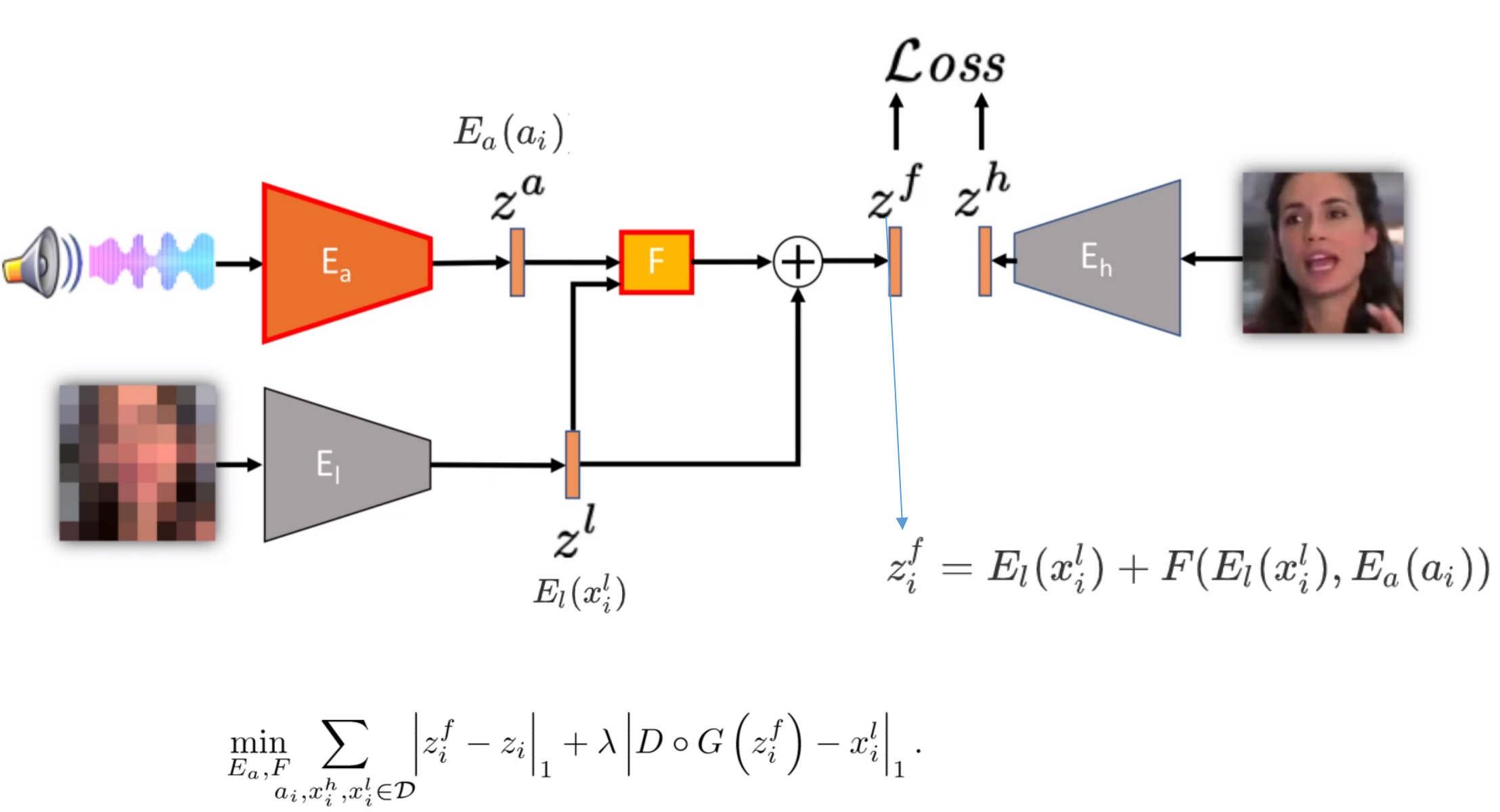
(a). matching inputs; (b) LR image与audio来自不同video
把LR image(8*8)输入到$E_l$得到latent representation, fusion network 融合$E_a$编码后的音轨和encoded LR image, 这一部分与前面的latent representation相加得到的新的latent representation 与预先训练得到的HR image的latent representation很相似,再通过decoder G输出HR图像
共有3个mappings:
- audio to HR (speech2face是用预训练的人脸识别网络作为额外监督,而我们的方法是完全无监督的)
- LR to HR
- LR+audio to HR
Experiments
dataset: VoxCeleb2 Dataset, 包含145K 人说话的video
2M frames at 128*128 pixels. 将每个speaker的一半的数据放入$\mathcal{D_{pre}}$
test set: 同人的不同video.
audio to image
简单的比较了一下他们的audio-only model ($E_a+G$) 和speech2Face

第一行是speech2face的结果,第二行是他们的audio2image的结果 ($E_a+G$)
性别分类:96%~97%准确率(没有在性别分类上与speech2face比,因为speech2face训练时用了分类器的监督)
classification as a performance measure
预训练好的 身份分类器、性别分类器、年龄分类器
closed set:training set和test set用同一个人的不同video
open set:training set和 test set不同人
ablations
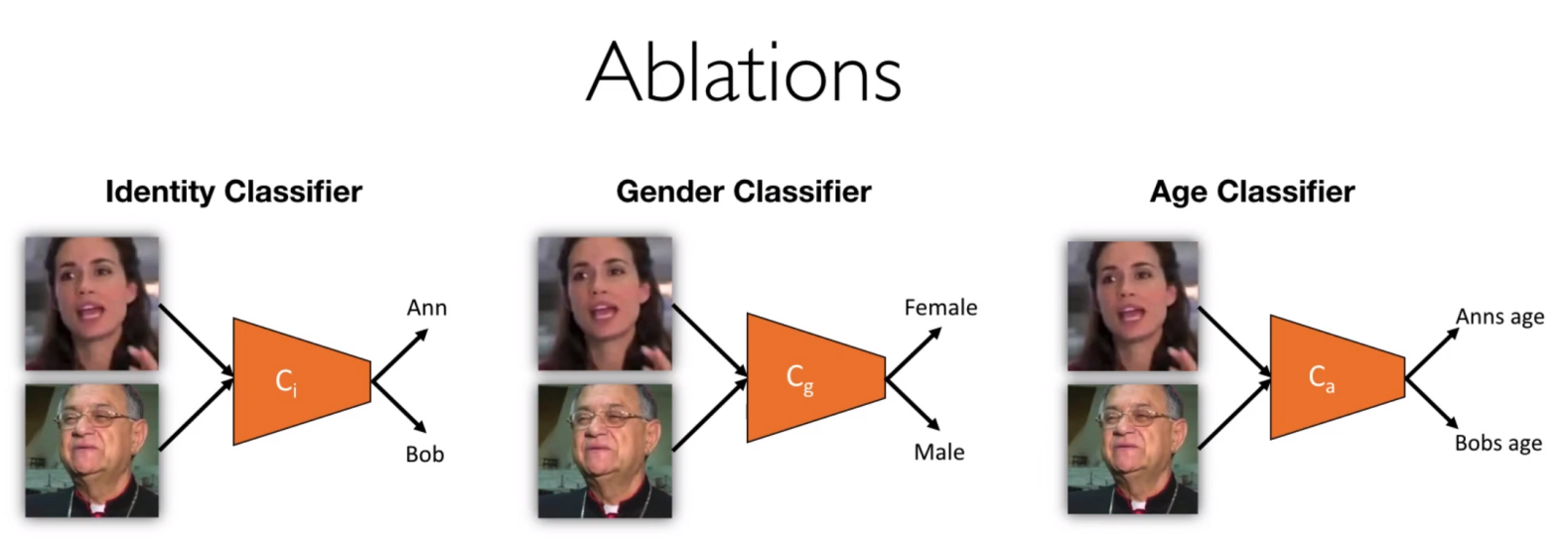
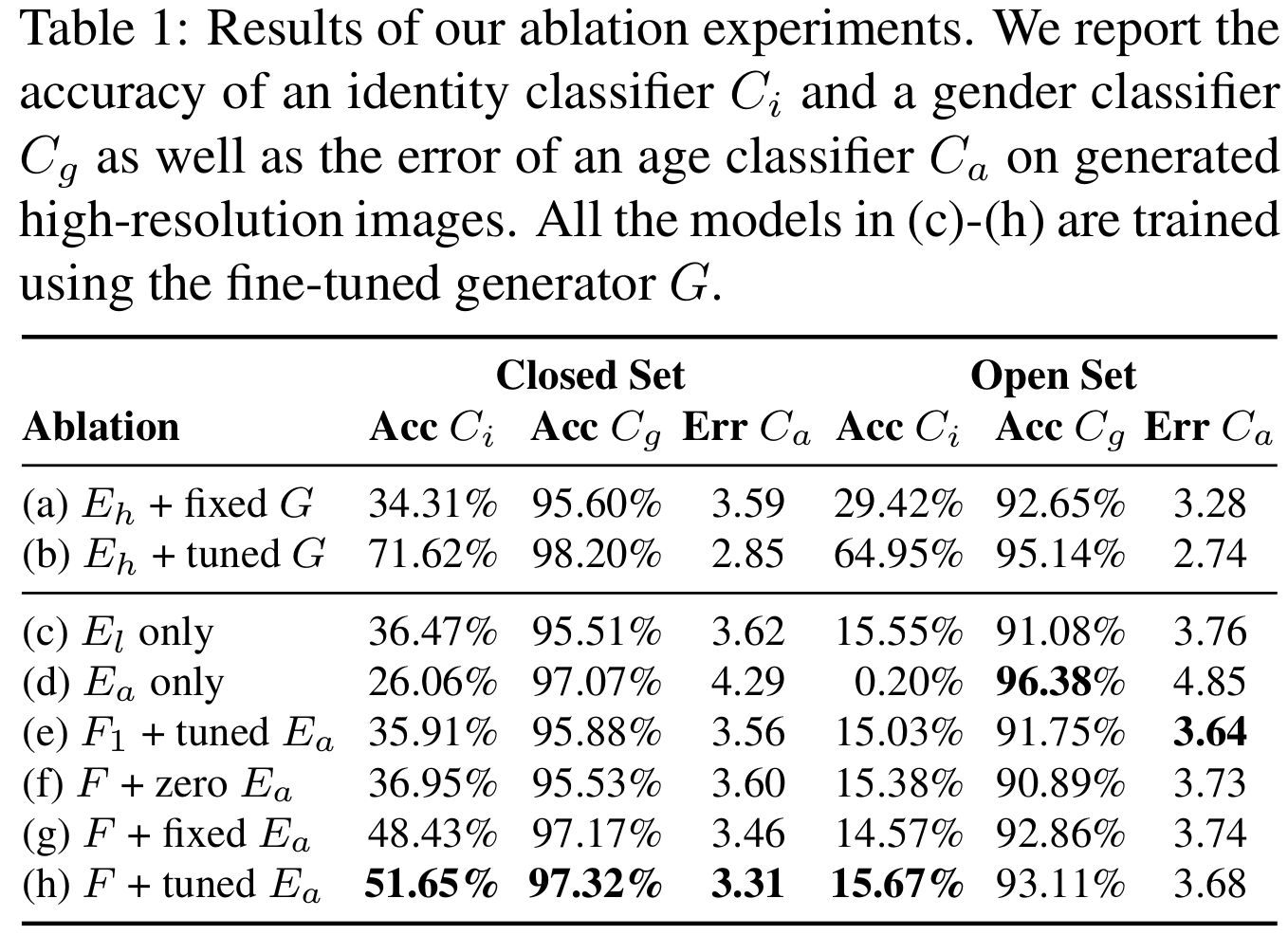
(a), (b): 训练$E_h$后时候和$G$一起fine-tune 【(b): HR 图像的表现,upper bound】
(c), (d):without fusion F。只要LR 或者只要音频
c与d相比,Audio更能提供性别信息。$\mathcal{C}_g$
(e)~(h): (f)(g)(h)相比:不加audio<固定audio encoder<fine-tuning
(e)与(h)相比:一个全连接层<三个全连接层
(g)与(h)相比:在训练fusion网络时也fine-tuning $E_a$ 对结果有些许提升。
gender和age在open set上也能预测比较准确。
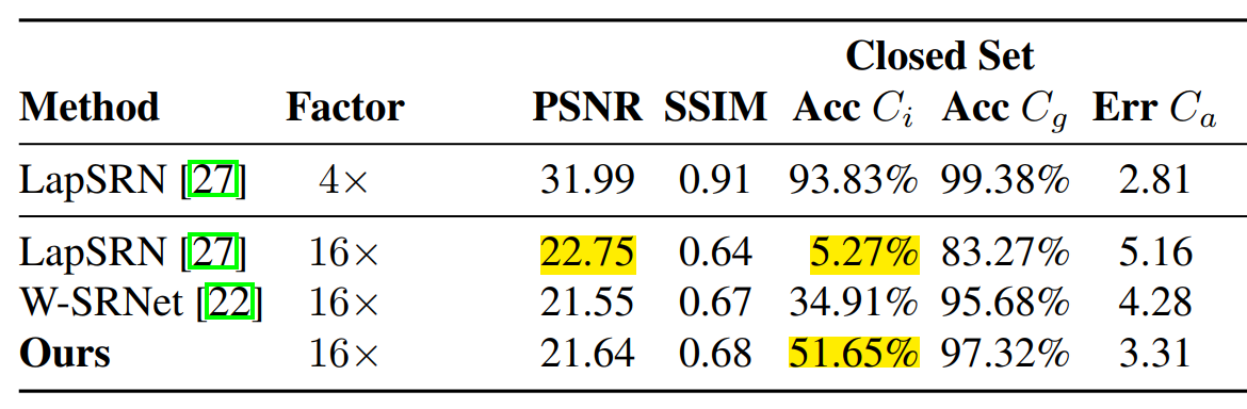
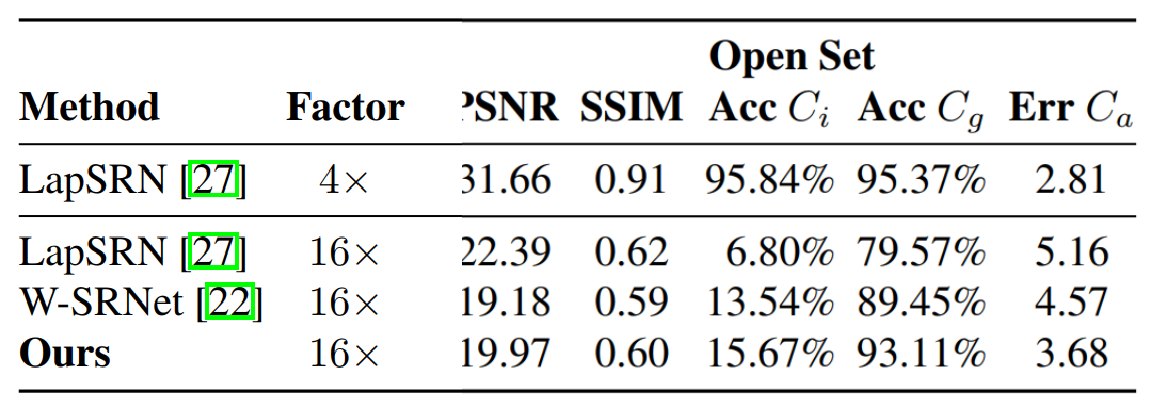
comparisons to other SR methods
LapSR(CVPR 2017) , W-SRNet (ICCV 2017 人脸SR) 在这个数据集上重新训练。

mixing
给定LR,与不同的audio混合

failure cases
