出处:CVPR2020
motivation
unpaired super-resolution,当aligned 的HR-LR training set is unavailable.
deviation between the generated LR distribution and the true LR distribution causes train-test discrepancy
contribution
(author: propose a new training method that overcomes the shortcomings of the existing GAN based unpaired super-resolution methods: generated LR distribution and the true LR distribution causes train-test discrepancy)
- bridge the gap between the well-studied existing SR methods and the real-world SR problem without paired datasets.
- Because our correction network is trained on not only the generated LR images but also the true LR images through the bi-directional structure (因为我们的校正网络不仅通过生成的LR图像进行训练,而且还通过双向结构对真实的LR图像进行训练) : minimize the train-test discrepancy
- any existing SR networks and pixel-wise loss function can be integrated because the SR network is separated to be able to learn in a paired manner. (SR网络可以pair对的学习)
包含unpaired kernel/noise correction network和pseudo-paired SR network
unpaired kernel/noise correction network: 去除噪声、调整输入图像的kernel,从输入的HR图像生成pseudo-clean的LR图像
pseudo paired SR network: 学习pseudo-clean的LR image到输入的HR image的映射
SR网络独立于效验网络(correction network)
related works
paired SR:
VDSR, EDSR, RCAN,LapSRN,DBPN
blind SR [39,12,57]
由任意的kernel降质得到的LR,学习由这样的LR到HR的映射,但当真实图像不是以假设的degradation降质的,(degradation估计不准),就会让真实图像SR的任务很差。
ZSSR, IKC,
关于blind SR的研究很少涉及blur kernels以外的综合降质问题(比如noise,compression artifact)。
GAN based methods [51,4,56, 32]
可以直接学习LR 到HR的映射,不需要degradation的假设。
可以大致分为两类:一类是直接从LR image出发,在生成的HR image和真实的HR image之间加discriminator. 这种方式的确定是无法用pixel wise的loss,因为real HR是未知的。
另一类是,在HR到LR的过程加GAN,生成的LR image和真实的LR image之间加discriminator,使生成的LR尽可能逼近真实的LR image。然后生成的LR与原来的HR之间用pixel-wise的loss训练一个LR2HR的网络,也就是U。与cycleGAN的区别:HR端没有discriminator。缺点:生成的LR分布与真实的LR分布存在偏差,导致在training set和test set性能差别大。(当test set的图像分布在training set中完全没有)
ICCV 2017: DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
ICCV 2017: CycleGAN
ECCV 2018:To learn image super-resolution, use a gan to learn how to do image degradation first
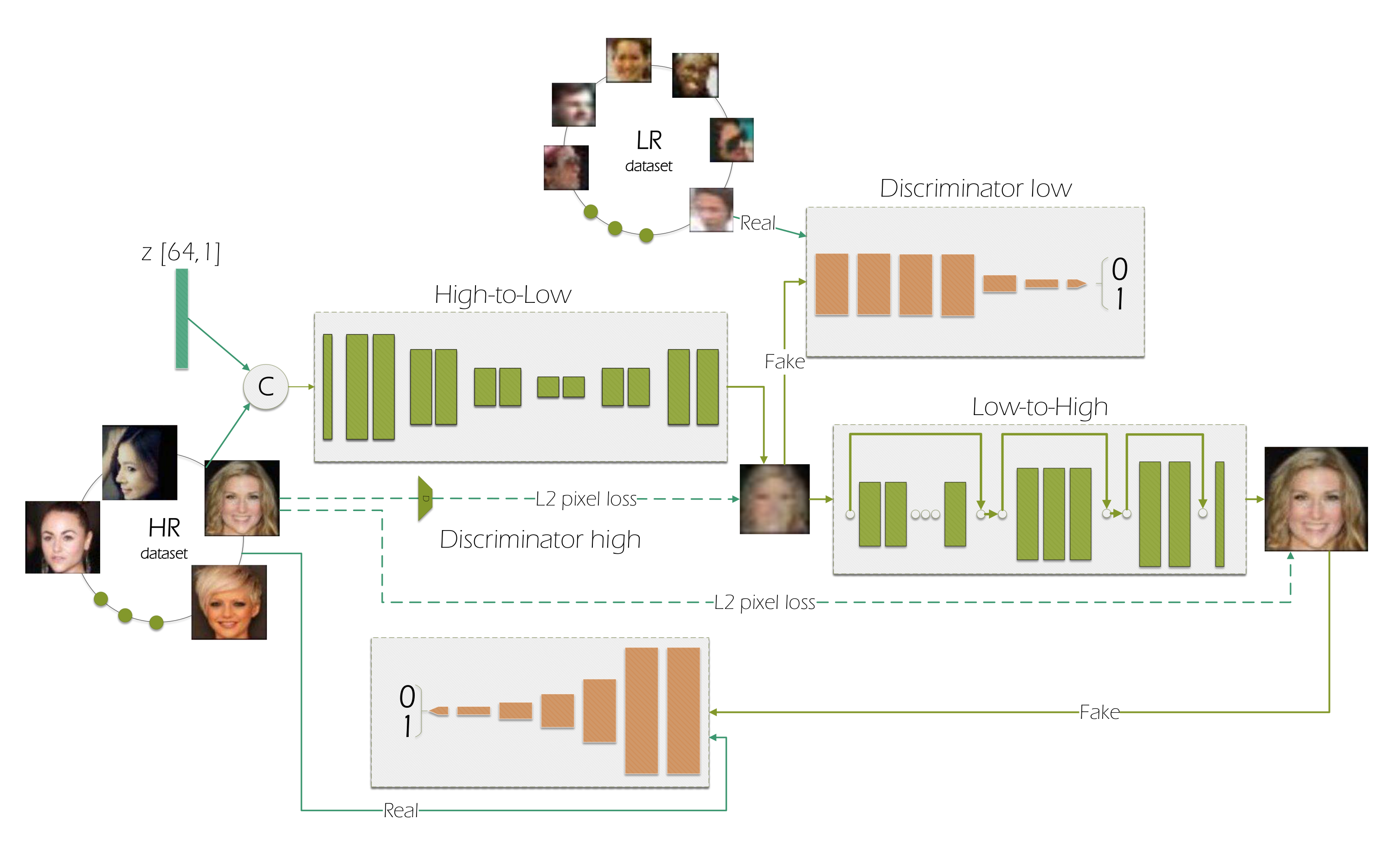
ICCVW 2019:Unsupervised learning for real-world super-resolution
以上两个第一次训练HR2LR的网络,并用degraded的输出训练LR2HR的网络。
CVPRW 2018:Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks
提出cycle-in-cycle network,但他们的degradation网络是确定的,并且SR网络与bi-cycle网络合在一起。选择loss function的时候有局限性
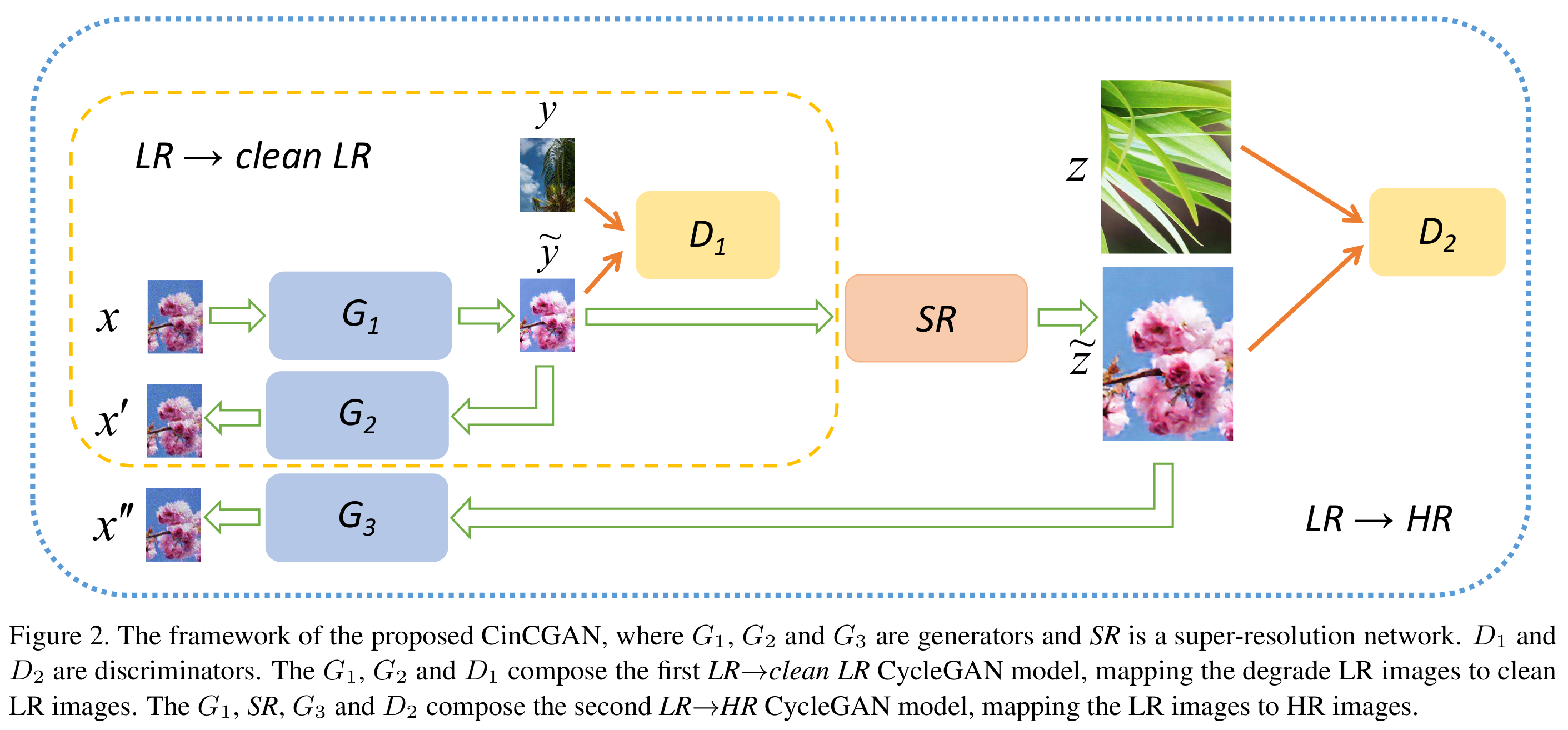
input LR $x$, GT HR $z$, $z$ bicubic下采样得到$y$ (clean LR)
先看里面的LR2clean LR,$x\sim x’ $ (半个cycleGAN)
生成得到的clean LR 进SR网络,与GT送入判别器$D_2$,通过$G_3$再回到real LR space,$x \sim x’’$
【pixel-wise loss不能用在HR space】
arxiv 2018:Unsupervised degradation learning for single image super-resolution
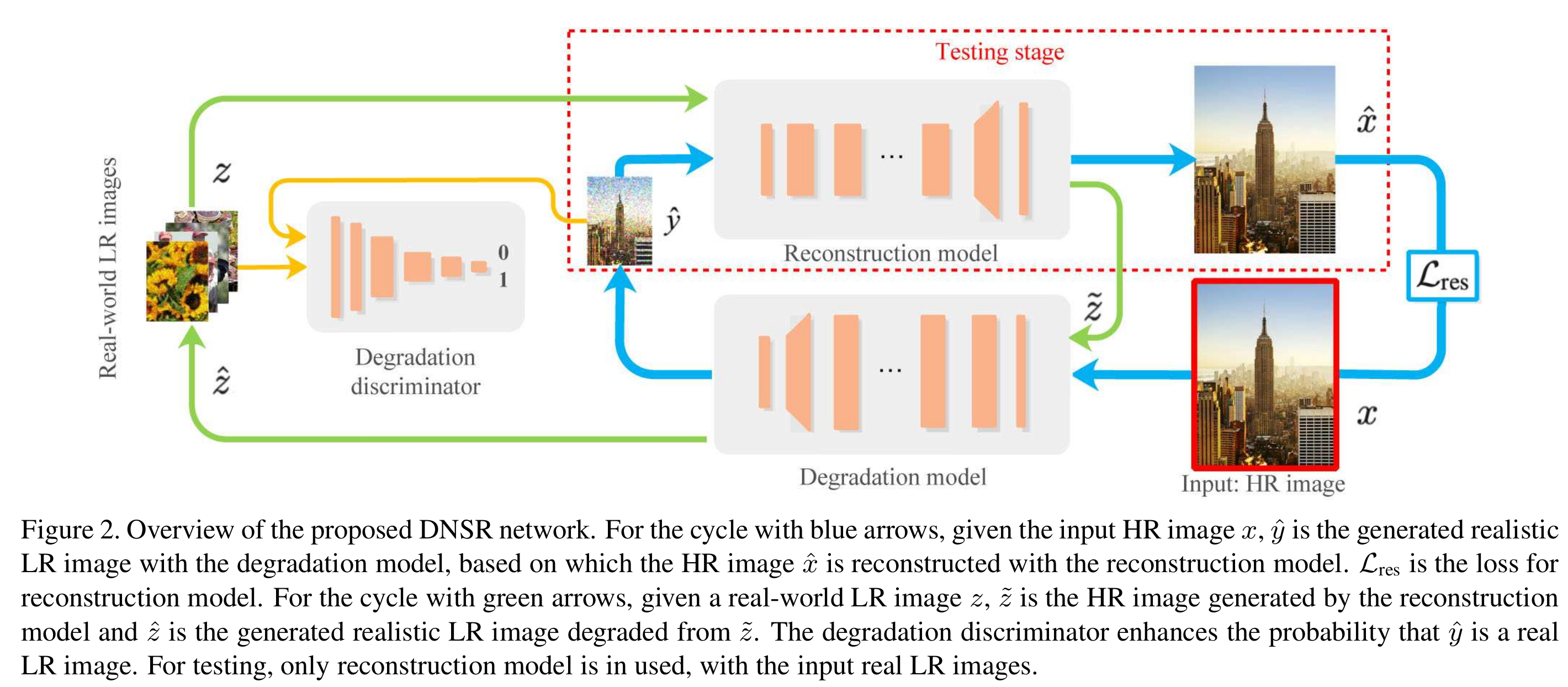
利用了双向的结构,他们也在选择loss function的时候有局限性
以上4种,ECCV 2018人脸的和arxiv 2018的这篇基本基于cycleGAN的结构。
这篇文章和以上这些文章最主要的区别是,解决了在训练数据集和测试数据集分布不一致的问题。也就是pseudo-clean LR 和 real LR
通过硬件和数据对齐的操作建立 real SR的数据集:
ICCV 2019:Toward real-world single image super-resolution: A new benchmark and a new model
CVPR 2019:Camera lens super-resolution
CVPR 2019:Zoom to learn, learn to zoom
method
解决其他GAN-based unpaired SR的缺点:separating the entire network into an unpaired kernel/noise correction network and a pseudo-paired
SR network
correction network:是一个cycleGAN, 完成的是unpaired的real LR和 clean LR之间的translation。clean LR由HR经过predetermined operation得到。
SR network:成对的学习pseudo-clean LR到HR mapping
在训练阶段,correction network也先由clean LR到true LR再回到clean LR生成pseudo-clean的LR 图像。SR network成对的学习pseudo-clean LR image到HR的mapping。
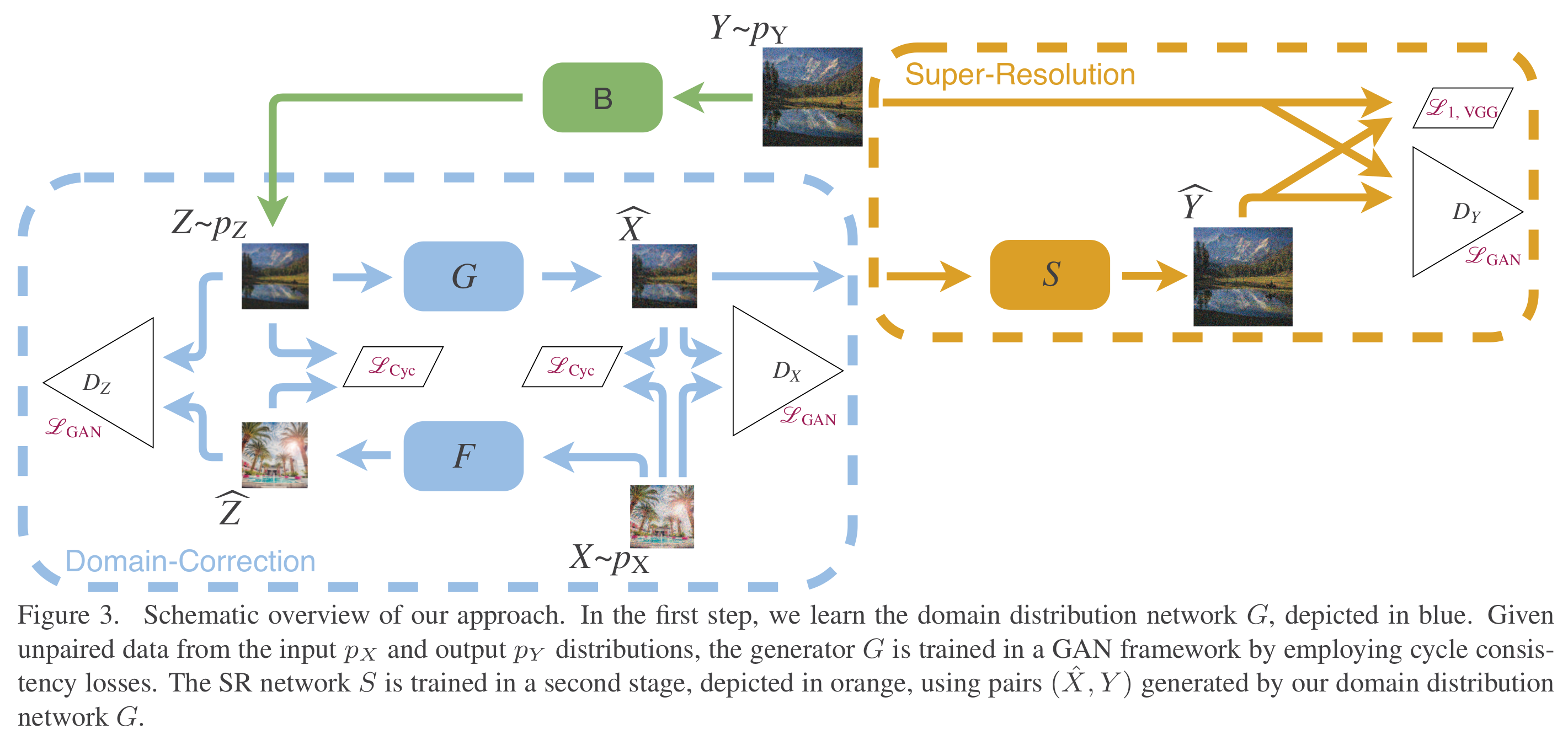
学习印射$F_{XY}:(X)LR->(Y)HR$, 定义 clean LR:$Y_\downarrow$是由$Y$经过一个指定的下采样操作得到的:$Y\rightarrow Y_\downarrow$是bicubic 下采样和gaussian blur的组合得到的。本文将$F_{XY}$拆分为两个mapping$G_{XY_\downarrow}$和$U_{Y_\downarrow Y}$的组合。
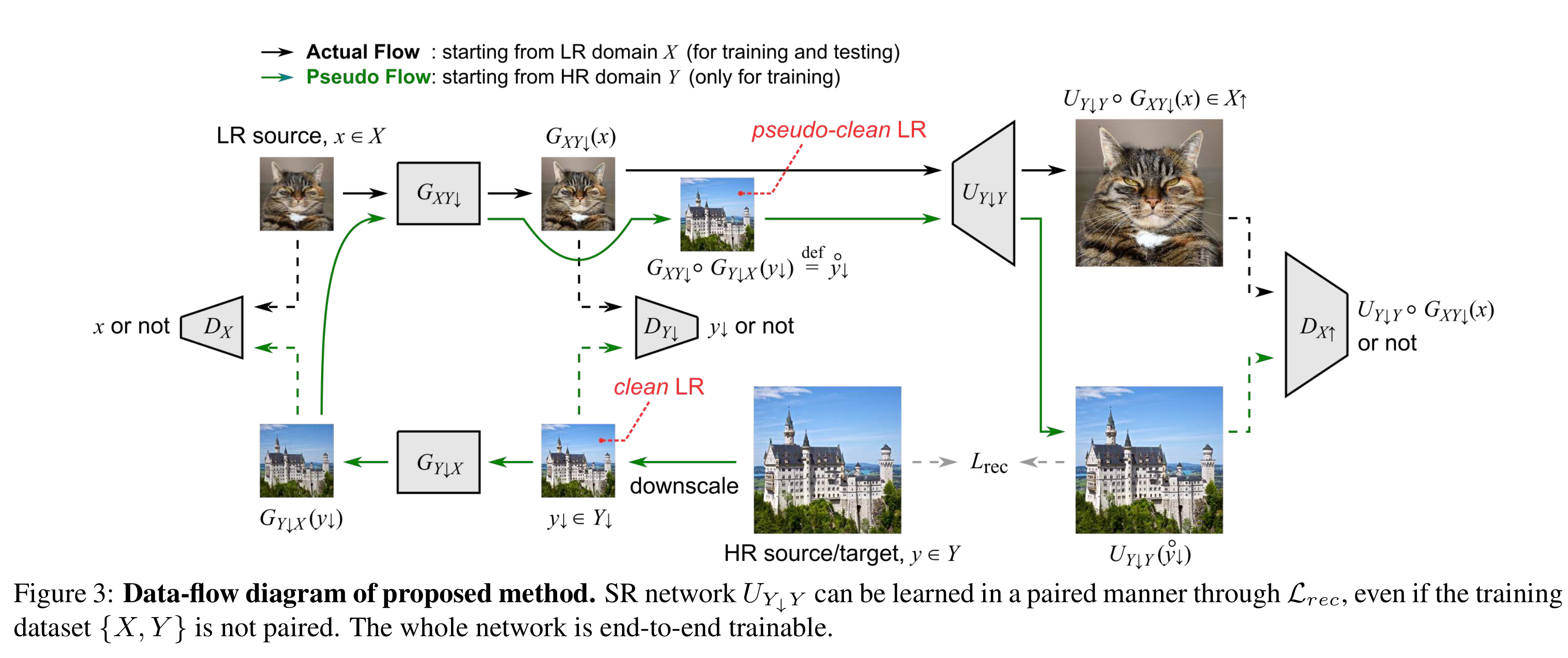
domain transfer in LR,其中学习mapping$G_{XY_\downarrow}$是通过上图蓝框中cycleGAN的结构
mapping from LR to HR,只看绿线部分,由HR domain出发,先经过bicubic+Gaussian的下采样得到clean LR $Y_\downarrow$, 再把它依次过cycleGAN的两个generator得到pseudo-clean LR $\mathring{y_{\downarrow}}$ , pseudo-clean LR到HR的mapping为$U_{Y_\downarrow Y}$. 而$\mathring{y_{\downarrow}}$和y是成pair的,所以经过$U_{Y_\downarrow Y}$上采样得到的$U_{Y_\downarrow Y}(\mathring{y_{\downarrow}})$与y 之间可以用任意的pixel-wise的loss。
HR discriminator, 希望减小训练和测试的偏差,尽管$\mathring{y_{\downarrow}}$用来训练SR网络,但是实际应用的时候,输入的LR image是$G_{XY_\downarrow}(x)$。所以pseudo clean LR和由real LR生成的clean LR的超分辨率后的差异尽可能小,所以最后还在这二者过$U_{Y_\downarrow Y}$的输出上加判别器$D_{X_\uparrow}$
test phase, 黑色实线部分,由real LR image先印射到 clean LR image $G_{XY_\downarrow}(x)$,(cycleGAN训练到比较理想情况的时候, clean LR 与由real LR生成的clean LR 以及pseudo clean LR都很接近)
loss function
对于两个生成器和3个判别器,总共的loss:
其中,$\mathcal{L}_{adv}((G_{XY_\downarrow},G_{Y_\downarrow X}),D_{X_\uparrow}, Y_\downarrow,X_\uparrow)$是HR discriminator的loss:
cycle consistency loss 被放松到只有单向的:
这使$G_{Y_\downarrow X}$可以一对多,满足不同的噪声和LR图像的分布。
identity loss在cycleGAN里用来保持图像的色彩,本文中也用了identity loss来避免色彩偏差:
geometric ensemble loss [CVPR 2019: Geometry consistent generative adversarial networks for one-sided unsupervised domain mapping] 减少可能的translation来保持场景的几何形状。本文中的geometric ensemble loss用来保证输入图像翻转、旋转不改变结果。
共带有8中翻转旋转模式。
而SR网络$U_{Y_\downarrow Y}$是与生成器、判别器无关的网络,只是用来放大图像的局部特征来作为HR端判别器的输入。用下式来更新SR网络:
这里的$\mathcal{L}_{rec}$可以由任意的pixel wise的loss代替。(perceptual loss, texture loss, adversarial loss)
network architecture
最上面那路的$G_{XY_\downarrow}$和 $U_{Y_\downarrow Y}$用RCAN的网络
而$G_{Y_\downarrow X}$的网络结构:resBlock+fusion layers+BN+Leaky ReLU
判别器:patchGAN,LR的判别器的stride=1,5层卷积, HR的判别器前面几层stride=2.
Experiments
synthetic distortions
DIV2K realistic-wild dataset (800 训练图像)
simulate : 4倍下采样、运动模糊、pixel shifting、加性噪声
每张图只有一种degradation,但是图像与图像之间的degradation不同,对于每张训练图像,合成4张降质图像。
训练:800 HR+3200 LR(unpair)
测试:100张validation set
超参:$\lambda_{cyc}=1, \lambda_{idt}=1,\gamma=0.1$, 4倍SR
intermediate images

compare with blind methods
blind denoising: NC [The noise clinic: a blind image denoising algorithm], RL-restore [ CVPR 2018: Crafting a toolchain for image restoration by deep reinforcement learning]
【blind denoising还有CVPR 2019: Toward Convolutional Blind Denoising of Real Photographs (Kai Zhang)】
blind deblurring: SRN-Deblur[CVPR 2018: Scale-recurrent network for deep image deblurring], DeblurGAN-v2 [Arxiv2019:Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better]
SR: DBPN(non-blind), ZSSR, IKC (blind)(zssr: CVPR2018, IKC: cvpr 2019)
ZSSR+KernelGAN
这些方法是用的各自论文里提及的数据集训练,没有在这里的数据集上训练。

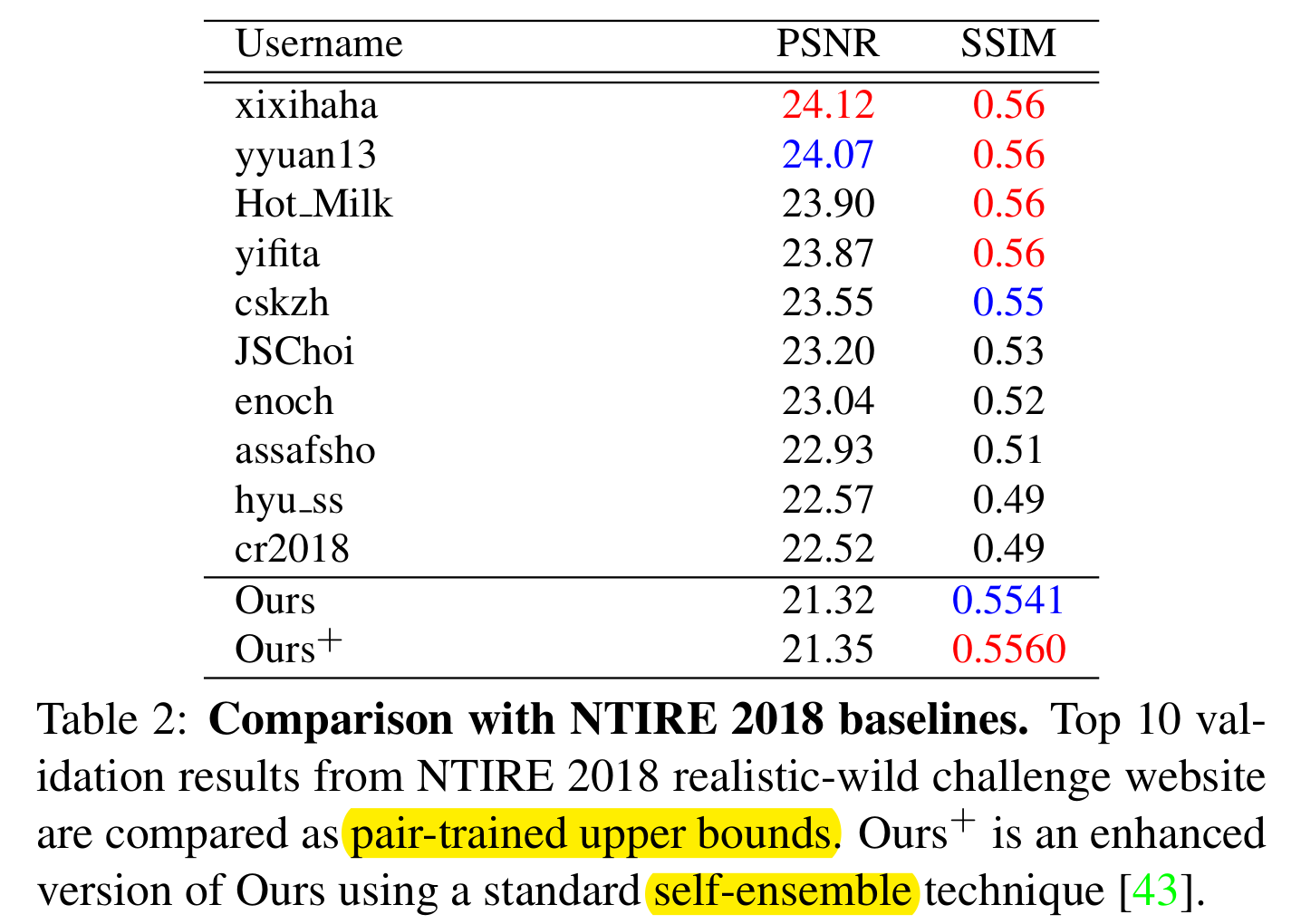
compare with NTIRE 2018 baselines 这些baseline是pair-trained (upper bounds) 这篇论文的方法PSNR比不过 baseline方法,但是SSIM与baseline方法相当. 因为PSNR高估了整体的亮度和色彩的细微差别,这些差别不会显著影响perceptual quality。
ablation study

第2行:去除HR的判别器
第3行:SR network是在$y_\downarrow$上训练的,而不是$\mathring{y_\downarrow}$上,这就相当于一个real LR和Gaussian+bicubic LR之间translation的网络(cycle GAN)加一个SR网络。
第4行:SR network是在$G_{Y_\downarrow X}(y_\downarrow)$ 上训练的,而不是$\mathring{y_\downarrow}$上. 相当于图1 的b
第5行:在第4行基础上,用RCAN官方的模型做validation。
perception-oriented training
在HR的$\mathcal{L}_{rec}$里加上perceptual loss, content loss (ESRGAN里面的),relativistic adversarial loss.
加上这些loss 后视觉效果比L1 loss好

realistic distortion 1
follow unsupervised 人脸SR [ECCV 2018: To learn image super-resolution, use a gan to learn how to do image degradation first]
HR face images: Celeb-A, AFLW, LS3D-W, VGGFace2 (64*64)
LR face images: 50000张Widerface 包含多种degradation(留出3000作为测试)(16*16)
他们实验发现identity loss加在x上比加在$y_\downarrow$ 上好。
超参:$\lambda_{cyc}=1,\lambda_{\bar{idt}}=2,\lambda_{geo}=1,\gamma=0.1$
训练2倍SR:32*32=>64*64
视觉指标FID比较:高亮的为基于GAN的unpaired的方法。

one-to-many degradation

realistic distortion 2
aerial image dataset DOTA
GSD (ground sample distances),
62 LR images GSD在[55cm, 65cm]之间, HR image的GSD为30cm
超参:$\lambda_{cyc}=1,\lambda_{\bar{idt}}=10,\lambda_{geo}=100,\gamma=0.1$ , 2倍SR
在这种数据集里,物体的像素点很少,所以对identity loss和geometric loss用了更大的权重。在训练初期,逐步提高geometric loss的权重。

只提供视觉上的比较,因为没有GT。
先用RL-restore(强化学习blind去噪修复)在input的LR image上去噪。但是他的输出over-smoothed. 即使再用SOTA的blind SR方法ZSSR超分辨,artifacts也不能被完全移除。
geometric loss的作用:

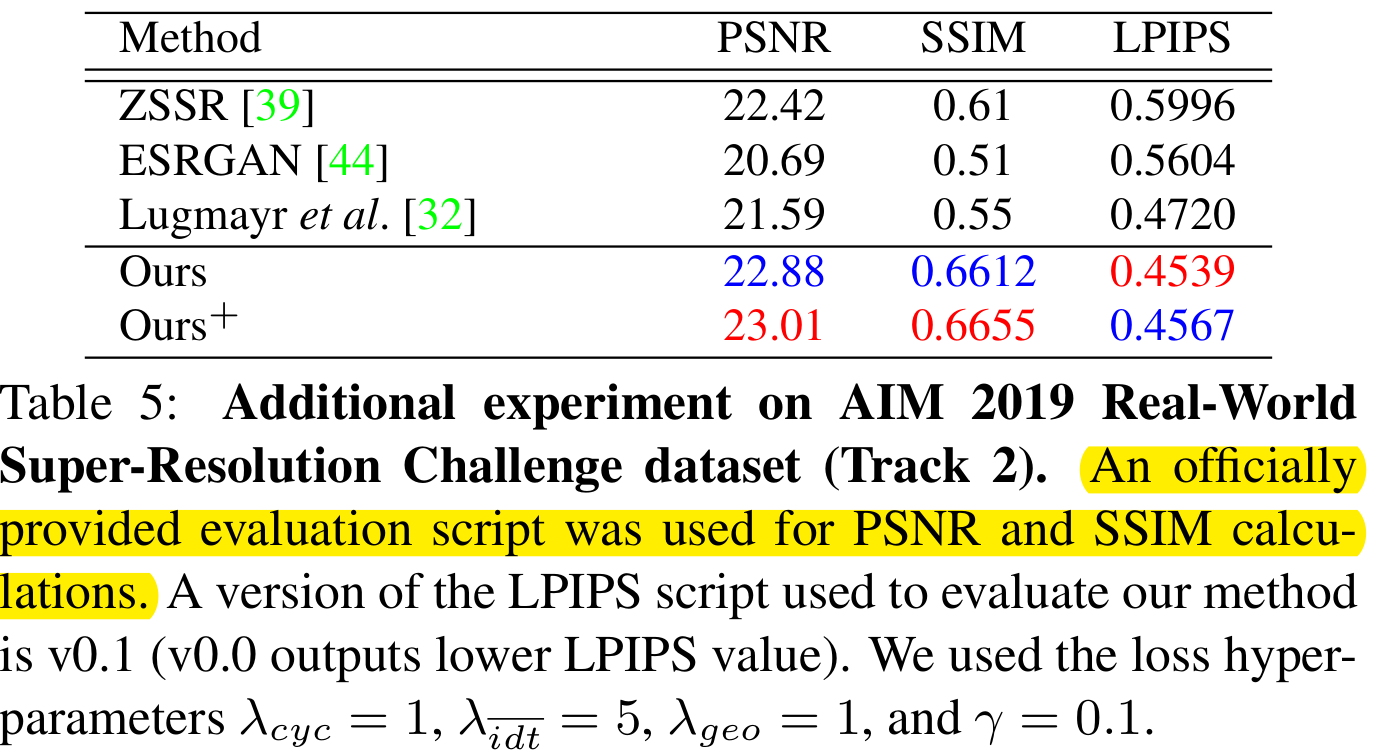
AIM 2019 real world SR challenge
没有HR-LR pair,测试时有官方的脚步来计算PSNR/SSIM。 $\lambda_{cyc}=1,\lambda_{\bar{idt}}=5,\lambda_{geo}=1,\gamma=0.1$
LPIPS: 视觉指标,越低越好。