出处:CVPR2019
motivation
- 之前的方法大多需要成对的训练数据,在实际中采集成对数据较困难。
- 现有的无监督方法比如cycleGAN这种,往往编码了色彩、纹理等模糊之外的信息。
contribution
- 提出了一直特定域的无监督特征解耦的去模糊方法。通过将模糊图像中的内容和模糊特征解开,以将模糊信息准确地编码到去模糊框架中。
- 他们在人脸图像和文本图像去模糊上达到了与最好的监督学习方法comparable的效果。
method
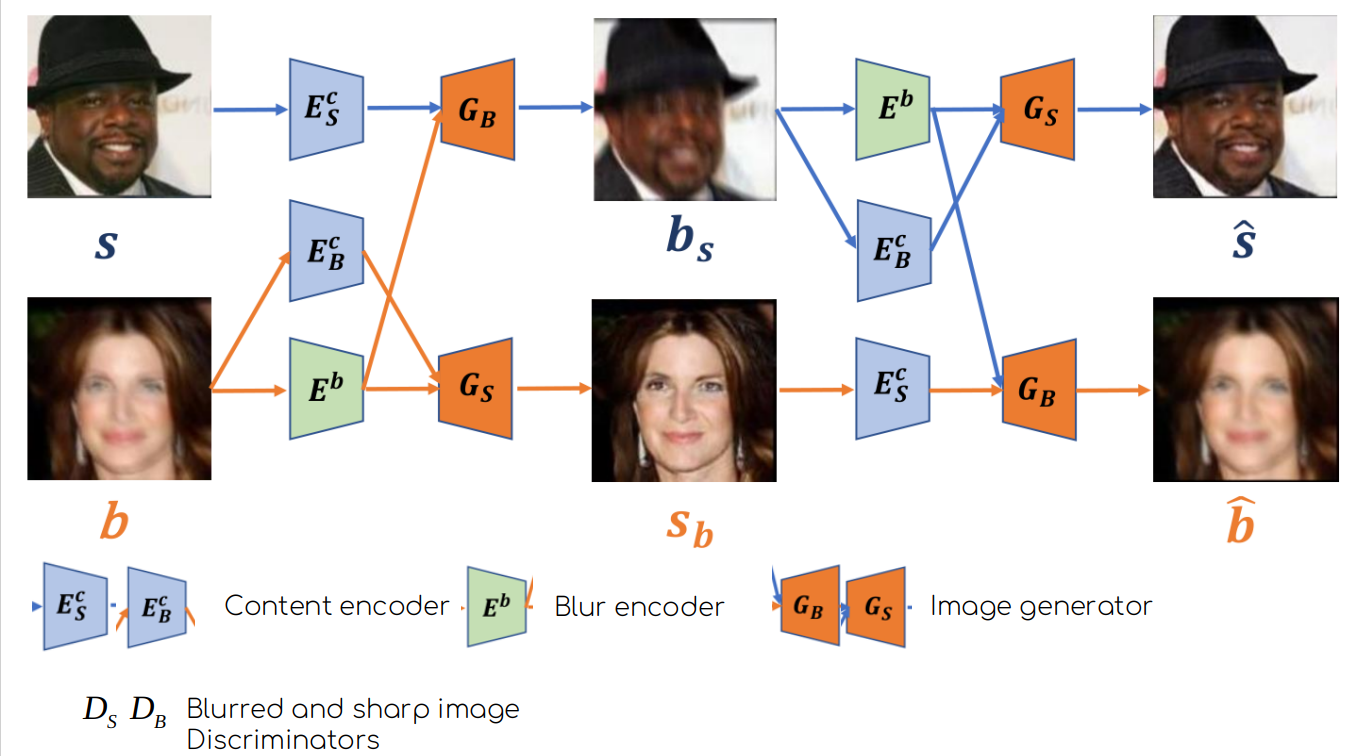
目的是实现图像的去模糊,为什么要添加模糊编码器?
作者的思路:既然清晰的图像是不含模糊信息的,可以认为,清晰图像的内容编码器提取到了清晰图像的内容信息,如果清晰的图像通过结合模糊编码器模糊特征去生成出模糊图像,是不是可以说,模糊编码器是在对清晰图像做模糊化处理,这个的前提就是 模糊编码器确实提取到了图像的模糊特征。所以说由清晰图像生成模糊图像也保证了模糊编码器是对图像的模糊信息进行编码的作用。清晰图像到模糊图像是为了优化模糊编码和模糊图像的内容编码的作用。
如何去保证这个模糊编码器是真的提取到模糊图像的模糊特征了呢?又怎么保证模糊图像的内容编码器真的提取到图像的内容信息?
- 让清晰图像内容编码器从清晰图像S 提取到的特征和模糊编码器从模糊图像b提取的模糊特征一同经过Gb生成模糊图像bs,并让bs是模糊化后的s,而不包含b的任何内容,也就是模糊编码器Eb不编码模糊图像的内容信息。
- 通过添加一个 KL 散度损失来规范模糊特征的分布,使其接近正态分布 p(z)∼N(0,1)。这个思路和 VAE 中的限制数据编码的潜在空间的分布思路是相近的,这里将模糊编码器的编码向量限制住,旨在控制模糊编码器仅对图像的模糊信息进行编码。

loss function
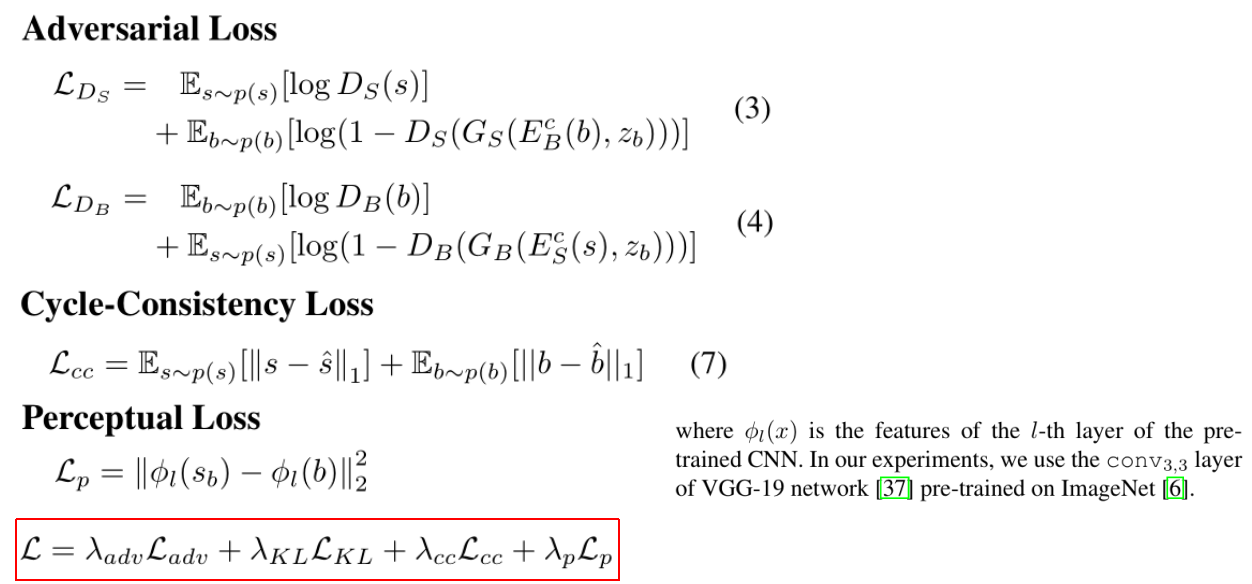
experiments
内容编码器由三个卷积层和四个残差块组成。模糊编码器包含四个卷积层和一个全连接层。
对于生成器,该架构与内容编码器对称,具有四个残差块,后面是三个反卷积层。
对于判别器, 采用多尺度结构,其中每个尺度的特征图经过五个卷积层,然后被送到 sigmoid 输出。
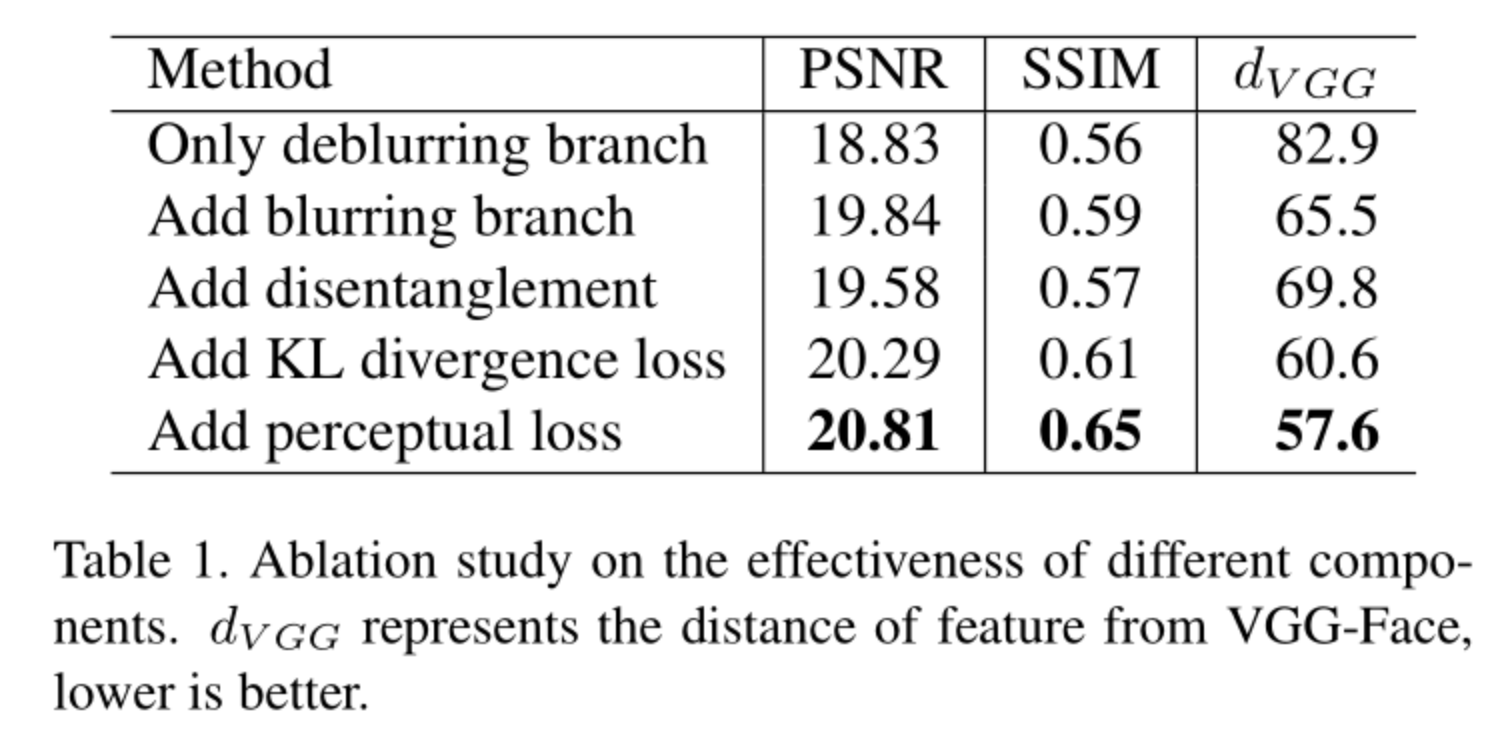
ablation study

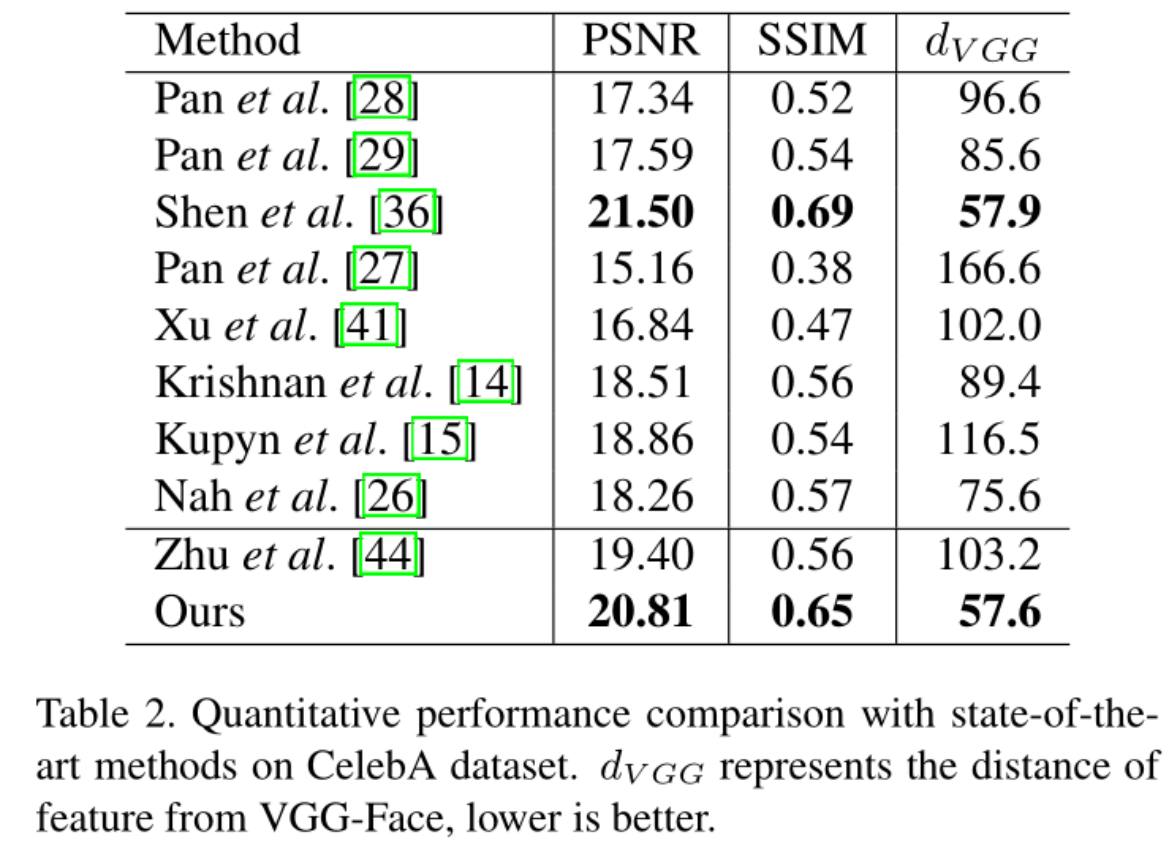
results